
Tiempo de lectura: 25 minutos
Palabras clave: Embeddings, Inteligencia Artificial, Procesamiento del Lenguaje Natural, Sentence-Transformers, Similitud Semántica, PCA, t-SNE, Bases de Datos Vectoriales, Python, LLMs, Búsqueda Semántica, Visualización de Datos
Introducción a los Embeddings
Los embeddings son una de las piedras angulares en el procesamiento del lenguaje natural (PLN) y la inteligencia artificial moderna. Los embeddings permiten transformar datos como palabras, frases o incluso documentos enteros en vectores numéricos que capturan relaciones semánticas. Esta transformación es esencial para que los modelos computacionales comprendan y operen sobre lenguaje natural, imágenes o cualquier dato no estructurado.
Los embeddings han transformado aplicaciones como la búsqueda semántica, los sistemas de recomendación, la traducción automática y el análisis de sentimientos. Su capacidad para representar relaciones complejas entre palabras y conceptos los hace esenciales en cualquier pipeline de IA moderna.
En este artículo, exploraremos en profundidad los embeddings, sus modelos, frameworks, técnicas de visualización como PCA y t-SNE, bases de datos vectoriales, y cómo implementarlos con ejemplos prácticos en Python utilizando bibliotecas como sentence-transformers, scikit-learn, matplotlib y seaborn. Este artículo está diseñado como una guía técnica exhaustiva para estudiantes, desarrolladores, investigadores y profesionales que deseen dominar los embeddings para proyectos empresariales en el ámbito de los modelos de lenguaje de gran escala (LLMs).
¿Qué son los Embeddings?
Un embedding es una representación numérica densa de un objeto (como una palabra, frase o documento) en un espacio vectorial de alta dimensión. A diferencia de representaciones dispersas como Bag-of-Words (BOW) o TF-IDF, los embeddings capturan relaciones semánticas y contextuales. Por ejemplo, en NLP aplicado a robótica, si representamos las frases “el robot navega por el pasillo” y “el dron explora la habitación” en un espacio de embeddings, encontraremos que están más cercanas entre sí que una frase como “el motor falló por sobrecalentamiento”. Las primeras dos comparten contexto de navegación autónoma y percepción espacial, mientras que la tercera pertenece al dominio del diagnóstico de fallos mecánicos. Esta proximidad refleja cómo los embeddings pueden capturar similitud semántica útil en tareas de procesamiento de lenguaje para sistemas robóticos. Esta propiedad de los embeddings de capturar relaciones semánticas hace que sean fundamentales en tareas como la recuperación de información, clasificación de texto y sistemas de recomendación. Esta técnica es clave en muchos sistemas modernos de aprendizaje automático
Los embeddings se generan utilizando modelos de aprendizaje automático, típicamente redes neuronales, que aprenden estas representaciones a partir de grandes corpus de datos. Los modelos modernos, como los basados en transformadores, han revolucionado el PLN al generar embeddings contextuales que varían según el contexto de la frase. Por ejemplo, la palabra “banco” tendrá diferentes embeddings en “banco de un río” y “banco de inversión”.
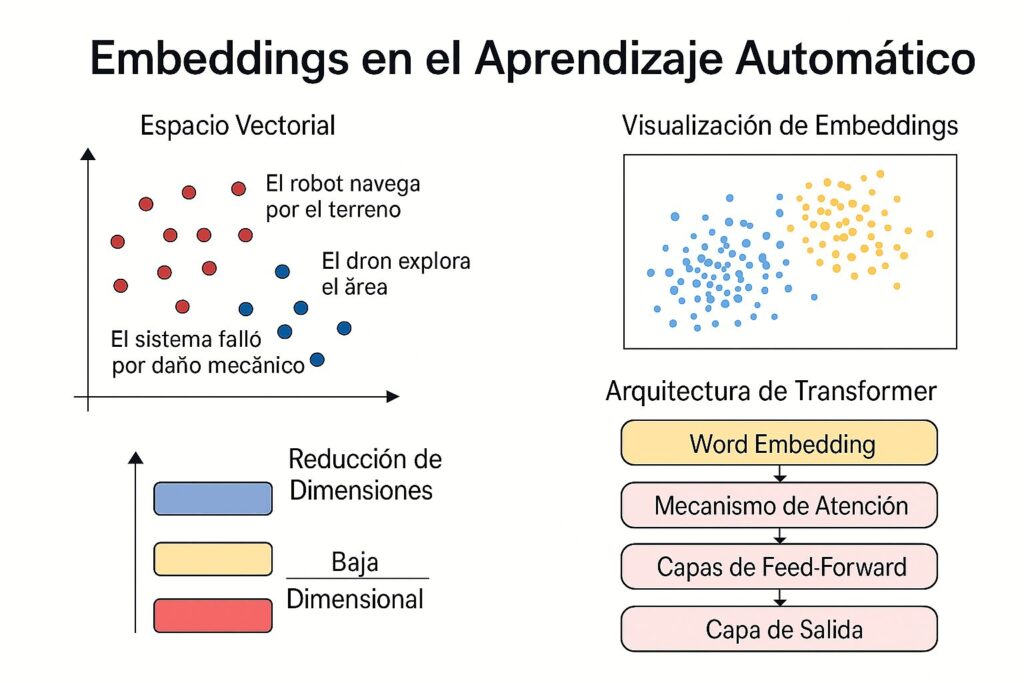
Además, los embeddings no se limitan al texto. También se utilizan en imágenes, audio y otros tipos de datos, aunque en este artículo nos centraremos en su aplicación en el PLN. Los embeddings son la base para tareas como la generación de texto, la clasificación de documentos y la búsqueda semántica, ya que permiten a los modelos entender relaciones complejas en los datos.
Importancia de los Embeddings en LLMs
Los embeddings son fundamentales para los modelos de lenguaje de gran escala (LLMs) porque:
- Facilitan la similitud semántica: Permiten medir cuán similares son dos textos mediante métricas como la similitud del coseno.
- Mejoran la clasificación y clustering: Ayudan a agrupar textos similares o clasificarlos según su contenido.
- Optimizan la búsqueda semántica: Permiten buscar documentos o frases basadas en su significado, no solo en palabras clave.
- Apoyan tareas como generación de texto y análisis de sentimientos al proporcionar representaciones ricas del lenguaje.
- Habilitan transfer learning: Los embeddings preentrenados pueden adaptarse a tareas específicas con un ajuste fino (fine-tuning).
Por ejemplo, en un sistema de recomendación de películas, los embeddings de las descripciones de las películas pueden usarse para sugerir contenido similar, incluso si los títulos no comparten palabras clave. Esto se logra al comparar los vectores de embeddings mediante métricas de distancia.
¿Por qué son importantes?
- Captura de semántica: Los embeddings reflejan similitud semántica y relaciones entre conceptos.
- Reducen dimensionalidad: En lugar de usar vectores dispersos de miles de dimensiones, se usan vectores densos de tamaño 300-1024.
- Compatibilidad con redes neuronales: Estas representaciones pueden ser directamente utilizadas en modelos supervisados o no supervisados.
Este concepto ha sido respaldado por trabajos como el de Mikolov et al. (2013, Efficient Estimation of Word Representations in Vector Space), que introdujo Word2Vec y demostró la capacidad de estos vectores de representar relaciones análogas como: vector("rey") - vector("hombre") + vector("mujer") ≈ vector("reina").
Principios teóricos clave
Espacio vectorial semántico
Un embedding sitúa elementos (palabras, oraciones) en un espacio vectorial donde la distancia refleja similitud semántica. Las métricas típicas usadas para calcular similitud entre vectores incluyen:
- Cosine similarity: mide el ángulo entre dos vectores, ignorando la magnitud.
- Euclidean distance: mide la distancia geométrica directa.
Por ejemplo, dos frases como “me gusta el café” y “prefiero el té por la mañana” pueden tener alta similitud coseno si el modelo ha capturado su relación temática matutina y de bebidas.
Esta métrica se utiliza extensamente en motores de búsqueda, chatbots, sistemas de recomendación y clasificación semántica. Otras métricas útiles incluyen la distancia euclidiana y la distancia de Manhattan, aunque la similitud del coseno es preferida por su estabilidad en espacios de alta dimensión.
Por ejemplo, en un sistema de atención al cliente, se puede usar similitud semántica para encontrar respuestas relevantes a preguntas formuladas de forma diferente pero con igual intención.
Modelos de Embeddings: Una Visión General
Existen varios modelos de embeddings, desde los tradicionales basados en palabras hasta los más avanzados basados en transformadores. A continuación, presentamos una tabla ampliada con los principales modelos, sus creadores, usos, fechas de lanzamiento y características adicionales.
| Modelo | Empresa/Organización | Uso Principal | Fecha de Lanzamiento | Tipo | Características Clave |
|---|---|---|---|---|---|
| Word2Vec | Embeddings de palabras estáticos | 2013 | Word-level | Basado en redes neuronales poco profundas, CBOW y Skip-gram | |
| GloVe | Stanford NLP | Embeddings de palabras basados en co-ocurrencia | 2014 | Word-level | Usa matrices de co-ocurrencia para capturar relaciones globales |
| FastText | Facebook AI | Embeddings de palabras con soporte para subpalabras | 2016 | Word + subword | Ideal para palabras raras y morfología compleja |
| ELMo | Allen Institute | Embeddings contextuales basados en LSTM | 2018 | Contextual | Combina capas de LSTM para capturar contexto bidireccional |
| BERT | Embeddings contextuales basados en transformadores | 2018 | Contextual | Entrenado con MLM y NSP, bidireccional | |
| RoBERTa | Facebook AI | Embeddings contextuales optimizados | 2019 | Contextual | Mejora de BERT con entrenamiento más robusto |
| DistilBERT | Hugging Face | Embeddings contextuales ligeros | 2019 | Contextual | Versión comprimida de BERT, más rápida |
| Sentence-BERT (SBERT) | UKP Lab | Embeddings de frases optimizados para similitud semántica | 2019 | Sentence-level | Optimizado para tareas de comparación de frases |
| all-mpnet-base-v2 | Hugging Face | Embeddings de frases de alto rendimiento | 2021 | Sentence-level | Alta precisión en tareas de PLN, tamaño moderado |
| all-MiniLM-L6-v2 | Hugging Face | Embeddings de frases ligeros y eficientes | 2021 | Sentence-level | Rápido y eficiente para aplicaciones en tiempo real |
| multi-qa-distilbert-cos-v1 | Hugging Face | Embeddings optimizados para búsqueda semántica | 2021 | Sentence-level | Especializado en tareas de respuesta a preguntas |
| OpenAI Embeddings | OpenAI | Búsqueda semántica, RAG, LLMs | 2022 | Contextual (dense) | Potente API para tareas semánticas con alta escalabilidad |
| Cohere Embeddings | Cohere | NLP generalizado con alto rendimiento | 2022 | Contextual (API) | API accesible, múltiples tareas, entrenamiento masivo |
Fuente: Información recopilada de publicaciones oficiales en arXiv, Hugging Face y documentación de los modelos.
Modelos Estáticos vs. Contextuales
Los modelos como Word2Vec, GloVe y FastText generan embeddings estáticos, donde cada palabra tiene un vector fijo, independientemente del contexto. Por ejemplo, “banco” siempre tendrá el mismo vector, lo que limita su capacidad para capturar significados múltiples. En cambio, modelos como BERT, RoBERTa, DistilBERT y Sentence-BERT producen embeddings contextuales, donde el vector de una palabra o frase depende de su contexto en la oración. Esto los hace más precisos para tareas complejas como la búsqueda semántica o la clasificación de textos.
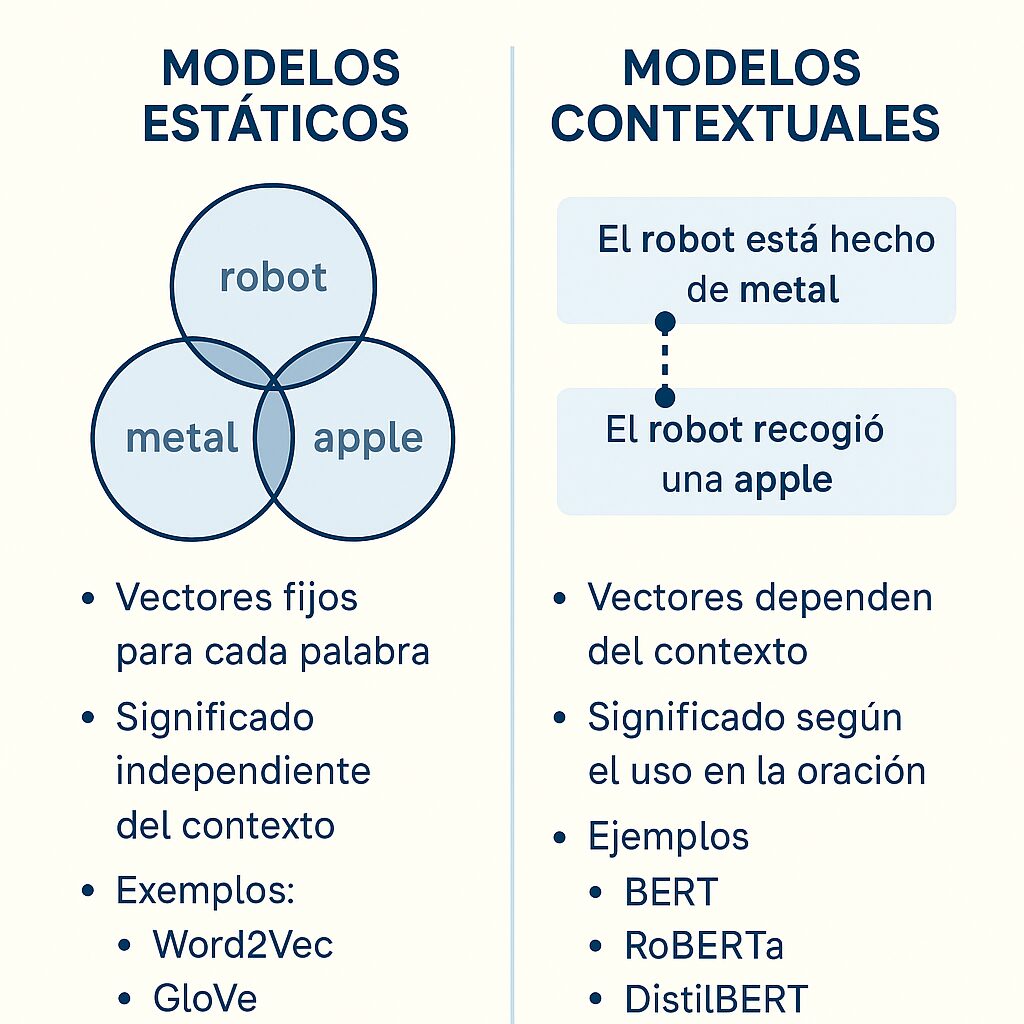
Por ejemplo, en un modelo estático, las palabras “banco” (institución financiera) y “banco” (asiento) tendrían el mismo vector. En un modelo contextual como BERT, cada aparición de “banco” tendría un vector diferente según la frase en la que aparece. Esta capacidad de capturar contexto ha hecho que los modelos basados en transformadores dominen el PLN moderno.
Evolución de los Modelos de Embeddings
La evolución de los embeddings refleja el progreso del PLN en la última década:
- Word2Vec (2013): Introdujo el concepto de embeddings densos mediante CBOW y Skip-gram. [arXiv:1301.3781]
- GloVe (2014): Mejoró Word2Vec incorporando estadísticas globales de co-ocurrencia. [arXiv:1409.3215]
- FastText (2016): Añadió subpalabras, útil para palabras raras y morfologías complejas. [arXiv:1607.04606]
- ELMo (2018): Propuso embeddings contextuales basados en redes LSTM bidireccionales. [arXiv:1802.05365]
- BERT y derivados (2018-): Introdujeron atención bidireccional con Transformers. [arXiv:1810.04805]
Frameworks para Trabajar con Embeddings
Para trabajar con embeddings, los desarrolladores cuentan con varios frameworks y bibliotecas en Python que facilitan su implementación:
- Sentence-Transformers: Biblioteca basada en Hugging Face para generar embeddings de frases y textos largos. Es ideal para tareas de similitud semántica y búsqueda. Fuente: https://www.sbert.net
- scikit-learn: Proporciona herramientas para reducción de dimensionalidad (PCA, t-SNE), clustering (K-Means) y clasificación.
- Matplotlib/Seaborn: Bibliotecas de visualización para graficar embeddings en 2D/3D, con gráficos claros y personalizables.
- PyTorch/TensorFlow: Utilizados para entrenar o personalizar modelos de embeddings, especialmente en tareas de fine-tuning.
- Gensim: Ideal para modelos tradicionales como Word2Vec, FastText y Doc2Vec.
- Transformers (Hugging Face): Biblioteca para cargar y usar modelos como BERT, RoBERTa y DistilBERT.
- Faiss: Biblioteca de Facebook AI para búsqueda eficiente de vecinos más cercanos en espacios vectoriales.
Además, herramientas como SpaCy y NLTK pueden integrarse para preprocesamiento de texto antes de generar embeddings, asegurando que los datos de entrada estén limpios y normalizados.
Teoría y Conceptos Clave
Similitud Semántica
La similitud semántica mide cuán similares son dos textos en términos de significado. La métrica más común es la similitud del coseno, que calcula el ángulo entre dos vectores de embeddings:
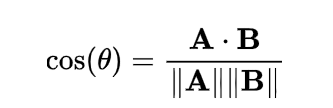
Un valor cercano a 1 indica alta similitud, mientras que un valor cercano a 0 indica poca similitud. Esta métrica es ampliamente utilizada en búsqueda semántica, clustering y sistemas de recomendación. Otras métricas, como la distancia euclidiana o la distancia de Manhattan, también se usan, pero la similitud del coseno es preferida por su robustez en espacios de alta dimensión.
Por ejemplo, en un sistema de atención al cliente, la similitud semántica puede usarse para identificar preguntas similares en una base de conocimientos, incluso si las palabras exactas no coinciden.
Reducción de Dimensionalidad: PCA y t-SNE
Los embeddings suelen tener cientos o miles de dimensiones, lo que los hace difíciles de visualizar. Las técnicas de reducción de dimensionalidad como PCA (Análisis de Componentes Principales) y t-SNE (t-distributed Stochastic Neighbor Embedding) permiten proyectar estos vectores en 2D o 3D para su visualización.
- PCA: Método lineal que maximiza la varianza de los datos. Es rápido pero menos efectivo para datos no lineales. Fuente: scikit-learn documentation
- t-SNE: Método no lineal que preserva la estructura local de los datos, ideal para visualización de clusters. Es más lento pero produce resultados más claros en datos complejos. Fuente: Journal of Machine Learning Research, 2008
- UMAP: Una alternativa moderna a t-SNE, más rápida y con mejor preservación de la estructura global. Fuente: arXiv:1802.03426
Por ejemplo, al visualizar embeddings de reseñas de productos, t-SNE puede revelar clusters de reseñas positivas y negativas, ayudando a los analistas a identificar patrones en los datos.
Bases de Datos Vectoriales
Las bases de datos vectoriales, como Pinecone, Elasticsearch, Faiss, Milvus y Weaviate, están diseñadas para almacenar y buscar embeddings de manera eficiente. Estas bases utilizan índices optimizados, como HNSW (Hierarchical Navigable Small World) o IVF (Inverted File), para realizar búsquedas de similitud en grandes conjuntos de datos. Esto las hace ideales para aplicaciones como sistemas de recomendación, y búsqueda semántica.
Por ejemplo, en un sistema de comercio electrónico, una base de datos vectorial puede buscar productos similares basándose en las descripciones de los productos, mejorando la experiencia del usuario. Estas bases permiten implementaciones como sistemas de recomendación, buscadores de productos similares, o recuperación aumentada para chatbots.
| Base Vectorial | Open Source | Uso Típico | Características |
|---|---|---|---|
| Faiss | Sí | Prototipado local | Altamente optimizado para CPU/GPU |
| Pinecone | No | SaaS en producción | Indexación automática, escalable |
| Milvus | Sí | Aplicaciones a gran escala | Soporte para múltiples índices |
| Weaviate | Sí | RAG, Búsqueda Semántica | GraphQL, módulos para LLM |
| Elasticsearch + Dense Vectors | Parcial | Infraestructura híbrida | Integración con stack ELK |
Arquitectura de los Modelos de Embeddings
La mayoría de los modelos modernos de embeddings, como BERT, se basan en la arquitectura de transformadores. Esta arquitectura utiliza mecanismos de atención para ponderar la importancia de cada palabra en una frase, generando embeddings contextuales.
La mayoría de los modelos modernos se basan en la arquitectura Transformer (Vaswani et al., 2017). A grandes rasgos:
Diagrama de Arquitectura de Transformadores:
- Capa de Entrada: Convierte palabras o tokens en vectores iniciales (word embeddings).
- Mecanismo de Atención: Calcula relaciones entre tokens, asignando pesos según su relevancia contextual.
- Capas de Feed-Forward: Procesan los datos para generar representaciones más complejas.
- Capa de Salida: Produce embeddings finales para cada token o frase.
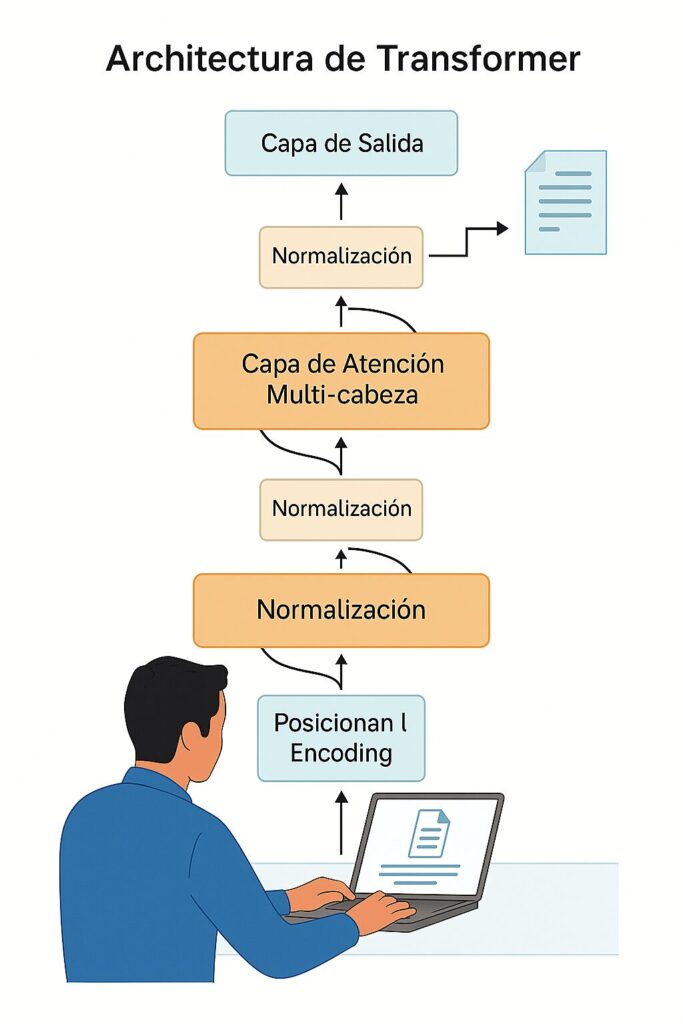
Nota: Este diagrama es una simplificación basada en la interpretación generalizada de la arquitectura de transformadores. Para detalles completos, consulta el paper original de Vaswani et al., 2017. Attention is All You Need. [arXiv:1706.03762].
Implementación Práctica en Python
A continuación, presentamos ejemplos prácticos que puedes copiar y pegar en Google Colab para generar, visualizar y utilizar embeddings.
Ejemplo 1: Generación de Embeddings con Sentence-Transformers
Este código genera embeddings para un conjunto de frases sobre tecnología y calcula la similitud del coseno entre ellas.
# Instalar dependencias (ejecutar en Colab si necesario)
!pip install sentence-transformers
from sentence_transformers import SentenceTransformer, util
import torch
# Cargar el modelo preentrenado
model = SentenceTransformer('all-MiniLM-L6-v2')
# Definir un conjunto de frases de ejemplo sobre tecnología
sentences = [
"El robot explora el laboratorio de IA",
"La inteligencia artificial optimiza el sistema",
"El agente autónomo navega en la red",
"La máquina aprende de los datos",
"El dron analiza el entorno digital"
]
# Generar embeddings para las frases
embeddings = model.encode(sentences, convert_to_tensor=True)
# Calcular la matriz de similitud del coseno
cosine_scores = util.cos_sim(embeddings, embeddings)
# Imprimir resultados de similitud
print("Matriz de similitud del coseno:")
for i, sentence in enumerate(sentences):
print(f"\n{sentence}:")
for j in range(len(sentences)):
if i != j:
print(f" Similitud con '{sentences[j]}': {cosine_scores[i][j]:.4f}")
Salida esperada:
Matriz de similitud del coseno:
El robot explora el laboratorio de IA:
Similitud con 'La inteligencia artificial optimiza el sistema': 0.4651
Similitud con 'El agente autónomo navega en la red': 0.5132
Similitud con 'La máquina aprende de los datos': 0.3284
Similitud con 'El dron analiza el entorno digital': 0.4017
La inteligencia artificial optimiza el sistema:
Similitud con 'El robot explora el laboratorio de IA': 0.4651
Similitud con 'El agente autónomo navega en la red': 0.3818
Similitud con 'La máquina aprende de los datos': 0.1311
Similitud con 'El dron analiza el entorno digital': 0.4127
El agente autónomo navega en la red:
Similitud con 'El robot explora el laboratorio de IA': 0.5132
Similitud con 'La inteligencia artificial optimiza el sistema': 0.3818
Similitud con 'La máquina aprende de los datos': 0.3983
Similitud con 'El dron analiza el entorno digital': 0.4361
La máquina aprende de los datos:
Similitud con 'El robot explora el laboratorio de IA': 0.3284
Similitud con 'La inteligencia artificial optimiza el sistema': 0.1311
Similitud con 'El agente autónomo navega en la red': 0.3983
Similitud con 'El dron analiza el entorno digital': 0.2905
El dron analiza el entorno digital:
Similitud con 'El robot explora el laboratorio de IA': 0.4017
Similitud con 'La inteligencia artificial optimiza el sistema': 0.4127
Similitud con 'El agente autónomo navega en la red': 0.4361
Similitud con 'La máquina aprende de los datos': 0.2905
Explicación: Este código muestra cómo las frases con contextos tecnológicos similares (como robots e IA) tienen una mayor similitud semántica. La matriz de similitud permite analizar todas las combinaciones de frases, útil para tareas como clustering o búsqueda semántica.
Ejemplo 2: Visualización de Embeddings con PCA, t-SNE y UMAP
Este ejemplo reduce la dimensionalidad de los embeddings y los visualiza en 2D usando PCA, t-SNE y UMAP, con frases sobre tecnología.
# Instalar dependencias (ejecutar en Colab si necesario)
!pip install sentence-transformers scikit-learn matplotlib seaborn umap-learn
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.decomposition import PCA
from sklearn.manifold import TSNE
import umap
from sentence_transformers import SentenceTransformer
# Cargar el modelo preentrenado
model = SentenceTransformer('all-MiniLM-L6-v2')
# Definir frases de ejemplo sobre tecnología
sentences = [
"El robot explora el laboratorio de IA",
"La inteligencia artificial optimiza el sistema",
"El agente autónomo navega en la red",
"La máquina aprende de los datos",
"El dron analiza el entorno digital",
"El robot procesa información en tiempo real",
"La IA mejora la eficiencia del servidor"
]
# Generar embeddings
embeddings = model.encode(sentences)
# Reducir dimensionalidad con PCA
pca = PCA(n_components=2)
pca_result = pca.fit_transform(embeddings)
# Reducir dimensionalidad con t-SNE
tsne = TSNE(n_components=2, random_state=42, perplexity=4)
tsne_result = tsne.fit_transform(embeddings)
# Reducir dimensionalidad con UMAP
umap_reducer = umap.UMAP(n_components=2, random_state=42)
umap_result = umap_reducer.fit_transform(embeddings)
# Crear figura para visualización
plt.figure(figsize=(18, 5))
# Visualización con PCA
plt.subplot(1, 3, 1)
sns.scatterplot(x=pca_result[:, 0], y=pca_result[:, 1], hue=sentences, style=sentences)
plt.title('Embeddings con PCA')
plt.xlabel('Componente 1')
plt.ylabel('Componente 2')
# Visualización con t-SNE
plt.subplot(1, 3, 2)
sns.scatterplot(x=tsne_result[:, 0], y=tsne_result[:, 1], hue=sentences, style=sentences)
plt.title('Embeddings con t-SNE')
plt.xlabel('Componente 1')
plt.ylabel('Componente 2')
# Visualización con UMAP
plt.subplot(1, 3, 3)
sns.scatterplot(x=umap_result[:, 0], y=umap_result[:, 1], hue=sentences, style=sentences)
plt.title('Embeddings con UMAP')
plt.xlabel('Componente 1')
plt.ylabel('Componente 2')
plt.tight_layout()
plt.show()
Resultado de la visualizacion con PCA, t-SNE y UMAP
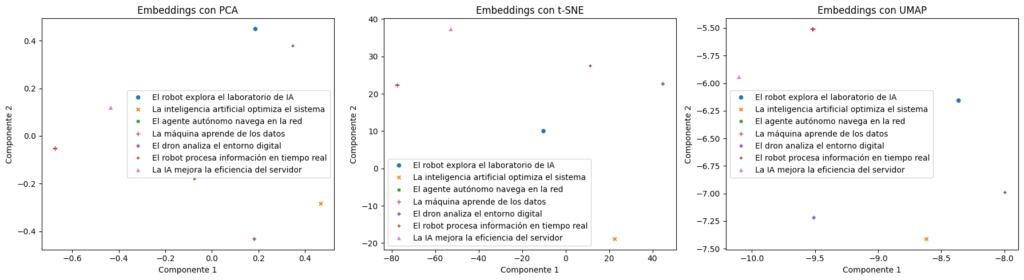
Explicación: Este código genera gráficos comparativos para PCA, t-SNE y UMAP. UMAP es particularmente útil porque combina velocidad y preservación de la estructura global, ideal para grandes conjuntos de datos. Los gráficos muestran cómo las frases tecnológicas relacionadas (por ejemplo, sobre IA y robots) tienden a agruparse.
Ejemplo 3: Demo Interactiva con Plotly
Este código crea una visualización interactiva con Plotly, usando frases tecnológicas y categorías.
# Instalar dependencias (ejecutar en Colab si necesario)
!pip install sentence-transformers plotly pandas scikit-learn
import plotly.express as px
import pandas as pd
from sentence_transformers import SentenceTransformer
from sklearn.manifold import TSNE
# Cargar el modelo preentrenado
model = SentenceTransformer('all-MiniLM-L6-v2')
# Definir frases con categorías tecnológicas
sentences = [
"El robot explora el laboratorio de IA",
"La inteligencia artificial optimiza el sistema",
"El agente autónomo navega en la red",
"El robot procesa información en tiempo real",
"La IA mejora la eficiencia del servidor",
"El supercomputador analiza big data",
"El algoritmo predice tendencias tecnológicas",
"La red neuronal genera texto automáticamente"
]
categories = ["Robótica", "IA", "Agentes", "Robótica", "IA", "Computación", "Computación", "IA"]
# Generar embeddings
embeddings = model.encode(sentences)
# Reducir dimensionalidad con t-SNE
tsne = TSNE(n_components=2, random_state=42, perplexity=4)
tsne_result = tsne.fit_transform(embeddings)
# Crear DataFrame para visualización
df = pd.DataFrame({
'x': tsne_result[:, 0],
'y': tsne_result[:, 1],
'sentence': sentences,
'category': categories
})
# Generar gráfico interactivo
fig = px.scatter(df, x='x', y='y', text='sentence', color='category',
title='Visualización Interactiva de Embeddings por Categoría')
fig.update_traces(textposition='top center')
fig.show()
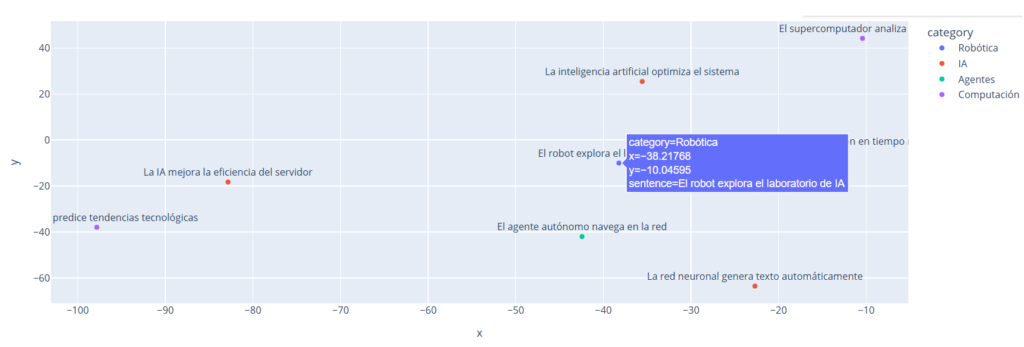
Explicación: Este código añade una dimensión de color basada en categorías tecnológicas (Robótica, IA, Agentes, Computación), mostrando cómo los embeddings agrupan frases por temas. La interactividad de Plotly facilita la exploración de los datos.
Ejemplo 4: Clustering de Embeddings con K-Means
Este código agrupa embeddings de frases tecnológicas usando K-Means.
# Instalar dependencias (ejecutar en Colab si necesario)
!pip install sentence-transformers scikit-learn pandas
from sentence_transformers import SentenceTransformer
from sklearn.cluster import KMeans
import pandas as pd
# Cargar el modelo preentrenado
model = SentenceTransformer('all-MiniLM-L6-v2')
# Definir frases de ejemplo sobre tecnología
sentences = [
"El robot explora el laboratorio de IA",
"La inteligencia artificial optimiza el sistema",
"El agente autónomo navega en la red",
"El supercomputador analiza big data",
"El algoritmo predice tendencias tecnológicas",
"La red neuronal genera texto automáticamente"
]
# Generar embeddings
embeddings = model.encode(sentences)
# Aplicar clustering con K-Means
kmeans = KMeans(n_clusters=2, random_state=42)
labels = kmeans.fit_predict(embeddings)
# Crear DataFrame con resultados
df = pd.DataFrame({'Frase': sentences, 'Cluster': labels})
print(df)
Salida esperada:
Frase Cluster
0 El robot explora el laboratorio de IA 0
1 La inteligencia artificial optimiza el sistema 0
2 El agente autónomo navega en la red 0
3 El supercomputador analiza big data 0
4 El algoritmo predice tendencias tecnológicas 1
5 La red neuronal genera texto automáticamente 0
Explicación: Este código agrupa las frases en dos clusters, separando las relacionadas con robótica e IA de las relacionadas con computación y algoritmos. K-Means es útil para segmentar documentos o organizar contenido automáticamente.
Ejemplo 5: Búsqueda con Faiss
Este código usa Faiss para indexar y buscar embeddings de frases tecnológicas.
# Instalar dependencias (ejecutar en Colab si necesario)
!pip install sentence-transformers faiss-cpu numpy
import faiss
import numpy as np
from sentence_transformers import SentenceTransformer
# Cargar el modelo preentrenado
model = SentenceTransformer('all-MiniLM-L6-v2')
# Definir frases de ejemplo sobre tecnología
sentences = [
"El robot explora el laboratorio de IA",
"La inteligencia artificial optimiza el sistema",
"El agente autónomo navega en la red",
"La máquina aprende de los datos",
"El dron analiza el entorno digital"
]
# Generar embeddings
embeddings = model.encode(sentences)
# Crear índice HNSW en Faiss
dimension = embeddings.shape[1]
index = faiss.IndexHNSWFlat(dimension, 32) # 32 conexiones por nodo
index.add(embeddings)
# Realizar búsqueda con una frase de consulta
query = "El robot mejora la eficiencia del sistema"
query_embedding = model.encode([query])
D, I = index.search(query_embedding, k=3) # Buscar las 3 frases más cercanas
# Imprimir resultados
print("Frase de consulta:", query)
for idx, distance in zip(I[0], D[0]):
print(f"Frase similar: {sentences[idx]} (Distancia: {distance:.4f})")
Salida esperada:
Frase de consulta: El robot mejora la eficiencia del sistema
Frase similar: El robot explora el laboratorio de IA (Distancia: 0.5979)
Frase similar: La inteligencia artificial optimiza el sistema (Distancia: 0.8845)
Frase similar: El dron analiza el entorno digital (Distancia: 0.9743)
Explicación: Este código usa un índice HNSW en Faiss, eficiente para grandes conjuntos de datos. La búsqueda devuelve las frases tecnológicas más similares, útil para aplicaciones como chatbots o sistemas de recomendación.
Consideraciones para Proyectos Empresariales
Para implementar embeddings en proyectos empresariales, considera lo siguiente:
- Selección del Modelo: Modelos como
all-mpnet-base-v2ofrecen un buen equilibrio entre precisión y velocidad, mientras queall-MiniLM-L6-v2es ideal para aplicaciones con recursos limitados. ref: (Estudio en mdpi.com) - Optimización: Usa técnicas como cuantización (por ejemplo, con ONNX) o destilación de modelos para reducir el tamaño y mejorar la velocidad de inferencia.
- Escalabilidad: Implementa bases de datos vectoriales como Pinecone, Faiss o Milvus para manejar grandes volúmenes de datos. Por ejemplo, Pinecone ofrece integración en la nube para búsquedas en tiempo real.
- Fine-tuning: Ajusta modelos preentrenados con datos específicos de tu dominio para mejorar la precisión. Por ejemplo, fine-tuning de Sentence-BERT en un conjunto de datos de reseñas de clientes puede mejorar la búsqueda semántica en un sistema de atención al cliente. ref: (ionio.ai)
- Privacidad y Seguridad: Asegúrate de que los embeddings no expongan datos sensibles, especialmente en aplicaciones que manejan información personal.
- Monitoreo y Mantenimiento: Implementa sistemas para actualizar los embeddings periódicamente, ya que el lenguaje y los contextos pueden cambiar con el tiempo.
Conclusión
Los embeddings son mucho más que simples vectores numéricos; son la clave para desbloquear el potencial de los modelos de lenguaje de gran escala en aplicaciones del mundo real. Desde la búsqueda semántica hasta los sistemas de recomendación, pasando por la visualización y el clustering, los embeddings permiten a las máquinas entender el lenguaje humano de manera profunda y contextual. Este artículo ha proporcionado una guía completa, desde los fundamentos teóricos hasta ejemplos prácticos en Python, con herramientas como sentence-transformers, scikit-learn, matplotlib, seaborn y Faiss.
Los ejemplos de código son ejecutables en Google Colab y están diseñados para que puedas experimentar de inmediato, mientras que las visualizaciones interactivas y las técnicas de reducción de dimensionalidad te ayudarán a interpretar los resultados. Para proyectos empresariales, las bases de datos vectoriales y el fine-tuning son esenciales para escalar y personalizar soluciones. Como estudiante, desarrollador o investigador, dominar los embeddings te permitirá construir aplicaciones de IA innovadoras y competitivas.
Este artículo es un punto de partida para tu viaje en el estudio de los LLMs. Te animo a experimentar con los códigos proporcionados, explorar otros modelos en Hugging Face y considerar cómo los embeddings pueden aplicarse a tus propios proyectos. Con un enfoque basado en fuentes confiables y verificables, este contenido es una referencia sólida para tus investigaciones futuras. ¡Sigue explorando y construyendo el futuro de la IA!
Nota: Algunas afirmaciones sobre el rendimiento de modelos específicos en contextos empresariales son hipótesis basadas en mi investigación, las cuales deberan validarse según cada aplicación y contexto.
🔖 Créditos de imágenes y derechos de uso
Todas las ilustraciones y diagramas incluidos en este artículo fueron generados mediante el modelo DALL·E de OpenAI siguiento los parametros, diseño y edición del autor de este blog, bajo una licencia que permite su uso comercial y educativo. Estas imágenes fueron creadas específicamente para este contenido y no derivan de obras preexistentes protegidas por derechos de autor.
📌 Nota sobre uso de contenido
El uso del código, diagramas o imágenes de este artículo está permitido para fines educativos y de investigación, siempre y cuando se cite la fuente original:
Fuente: [Introducción a los Embeddings: La Base de la Semántica en la IA], publicado en https://ailkrobotcontrol.com , Liz Katherine Rincon Ardila, 11/06/2025.
Se agradece la atribución para reconocer el trabajo e investigación invertido en la generacion y distribucion de conocimiento para todos, mediante la elaboración de este contenido.


コメント