
- Introducción a Self-Attention en Modelos de Lenguaje
- ¿Qué es Self-Attention?
- Cálculo paso a paso de self-attention con código
- Visualización de la matriz de atención
- Técnicas Avanzadas de Self-Attention
- Frameworks y Herramientas para Self-Attention
- 🧠 ¿En qué orden ocurre el self-attention en un Transformer?
- Implementación Práctica de Self-Attention
- Visualización de Self-Attention
- Aplicaciones Prácticas de Self-Attention
- 📊 ¿Qué es una matriz de atención?
- 🧠 Cómo leerla (fila por fila):
- 🎯 ¿Qué te dice esta matriz?
- 🧪 ¿Y qué viene después?
- Desafíos y Optimizaciones
- Consejos para Proyectos Empresariales
- Conclusión
- Referencias
Introducción a Self-Attention en Modelos de Lenguaje
El mecanismo de self-attention (autoatención) es la piedra angular de los modelos de lenguaje modernos, especialmente en la arquitectura Transformer, introducida en el artículo seminal de 2017 “Attention is All You Need” por Vaswani et al. Este mecanismo permite a los modelos de lenguaje procesar secuencias de datos de manera más eficiente que los métodos tradicionales como redes neuronales recurrentes (RNN) o convolucionales (CNN), capturando dependencias de largo alcance y procesando datos en paralelo. En este artículo, exploraremos en profundidad el concepto de self-attention, sus variantes, implementación práctica, y cómo utilizarlo en proyectos empresariales, con un enfoque en código ejecutable en Google Colab y visualizaciones con Streamlit.
Self-attention permite que cada token (palabra, subpalabra o símbolo) en una secuencia “preste atención” a otros tokens en la misma secuencia, ponderando su importancia según el contexto. Esto es fundamental para tareas de procesamiento de lenguaje natural (NLP) como traducción automática, generación de texto, y análisis de sentimientos. A continuación, desglosaremos los conceptos teóricos, los diferentes modelos, frameworks, y proporcionaremos ejemplos prácticos con código y visualizaciones.
¿Qué es Self-Attention?
Definición y Fundamentos
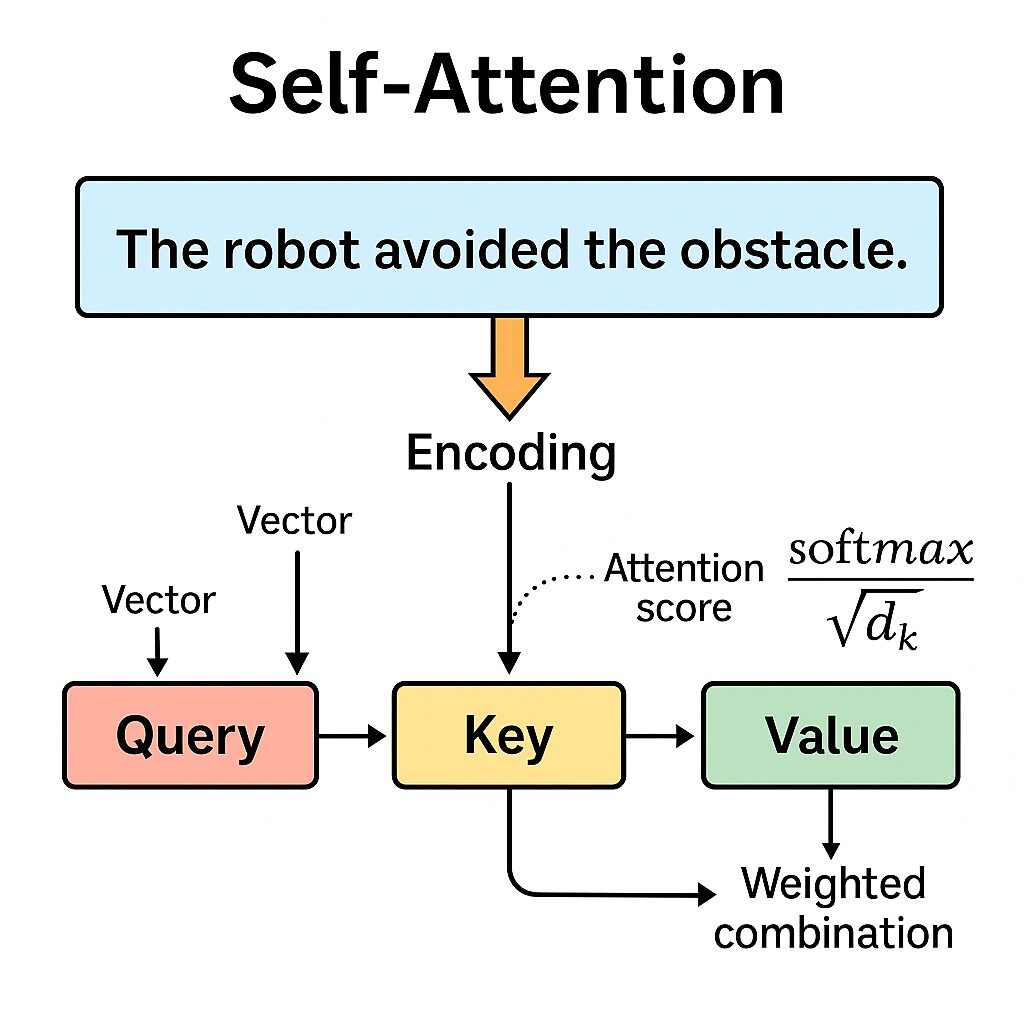
Self-attention es un mecanismo que permite a un modelo procesar una secuencia de entrada asignando pesos a cada token en función de su relación con los demás tokens en la secuencia. A diferencia de las RNN, que procesan tokens secuencialmente, self-attention permite que todos los tokens interactúen simultáneamente, capturando relaciones contextuales sin importar la distancia entre ellos. Esto resuelve problemas como el desvanecimiento del gradiente en secuencias largas. Self-attention permite que cada token de una secuencia “preste atención” a otros tokens, asignando pesos que reflejan su importancia contextual. Esta interacción se basa en tres vectores generados por cada token:
Value (V): “Qué información tiene el otro token”. Contiene la información que se ponderará según los pesos de atención calculados.
Query (Q): “Qué información busca este token”. Representa la “pregunta” que un token hace a los demás.
Key (K): “Qué representa este otro token”. Actúa como un identificador para cada token, permitiendo comparaciones.
Estos vectores se derivan de la multiplicación de los embeddings de entrada con matrices de pesos aprendidas durante el entrenamiento. La ecuación fundamental para calcular los attention scores es:
Donde:
- ( QK^T ) calcula la similitud entre queries y keys.
- (sqrt{d_k}) es un factor de escalado para estabilizar los gradientes, siendo ( d_k ) la dimensión de los vectores key.
- ( softmax) normaliza los scores para obtener pesos de atención.
Ventajas de Self-Attention
- Procesamiento Paralelo: A diferencia de las RNN, self-attention procesa todos los tokens simultáneamente, reduciendo el tiempo de entrenamiento.
- Dependencias de Largo Alcance: Captura relaciones entre tokens distantes en una secuencia.
- Flexibilidad: Aplicable a diversas tareas de NLP, desde traducción hasta generación de texto.
Cálculo paso a paso de self-attention con código
Vamos a implementar un ejemplo simple usando NumPy:
import numpy as np
# Ejemplo de vectores Q, K, V
d_k = 64
seq_len = 3
Q = np.random.randn(seq_len, d_k)
K = np.random.randn(seq_len, d_k)
V = np.random.randn(seq_len, d_k)
# Calcular attention scores
scores = np.matmul(Q, K.T) / np.sqrt(d_k)
attention_weights = np.exp(scores) / np.sum(np.exp(scores), axis=-1, keepdims=True)
output = np.matmul(attention_weights, V)
print("Pesos de atención:\n", attention_weights)Resultados del self-attention:
Pesos de atención:
[[0.39981144 0.14425011 0.45593845]
[0.36438574 0.54575417 0.08986009]
[0.02260998 0.17801675 0.79937327]]Visualización de la matriz de atención
import matplotlib.pyplot as plt
import seaborn as sns
# Visualizar matriz de atención
sns.heatmap(weights, annot=True, cmap='Blues')
plt.title("Matriz de Atención")
plt.xlabel("Keys")
plt.ylabel("Queries")
plt.show()Resultado de la matriz de atencion, donde tokens atendidos
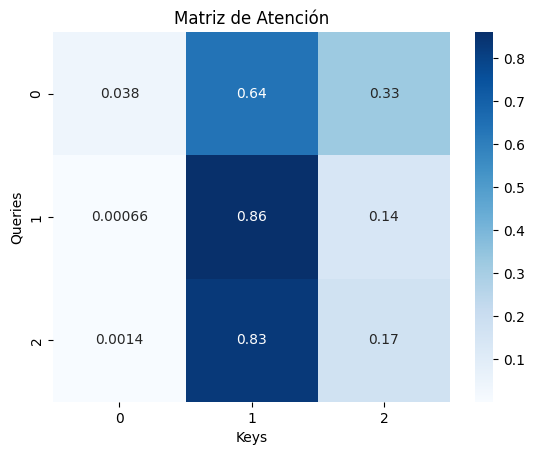
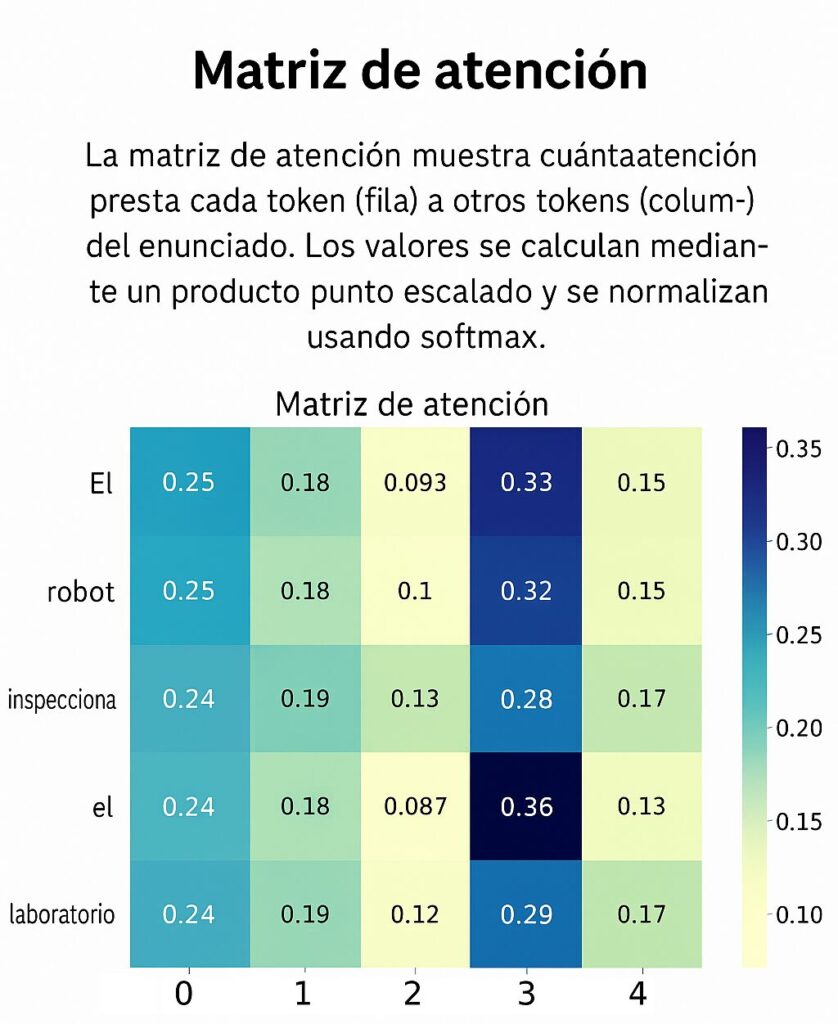
📊 Interpretación de la Matriz de Atención
La figura representa una matriz de atención generada por el mecanismo de self-attention en un modelo de lenguaje. En esta matriz, cada fila corresponde a un token que está prestando atención, mientras que cada columna representa un token al que se le presta atención. Los valores numéricos en cada celda (entre 0 y 1) indican cuánta atención se asigna entre esos dos tokens. Este valor se calcula mediante un producto punto escalado y se normaliza usando la función softmax, por lo que cada fila suma 1.
En el contexto de una frase como “El robot inspecciona el entorno del laboratorio”, los tokens podrían ser: ["El", "robot", "inspecciona", "el", "laboratorio"]. Si observamos la fila correspondiente al token “robot”, veremos que puede asignar mayor atención al token “inspecciona”, ya que su significado en esa frase depende del verbo. Del mismo modo, el token “el” podría prestar atención a “laboratorio”, especialmente si se repite en el contexto.
El color de cada celda indica la intensidad de atención: colores más oscuros significan mayor atención, mientras que los más claros indican menor peso. Una barra lateral de color (escala) muestra la gradación entre estos valores.
Esta visualización permite entender cómo el modelo contextualiza cada palabra, identificar relaciones sintácticas o semánticas, y mejorar la interpretabilidad de los modelos basados en Transformers.
Técnicas Avanzadas de Self-Attention
A medida que los modelos han crecido en capacidad y aplicaciones, también lo han hecho las variantes y extensiones del mecanismo de self-attention. Aquí exploramos algunas de las técnicas avanzadas más relevantes:
Scaled Dot-Product Attention
Es la forma básica de atención usada en el Transformer original, donde se calculan productos punto entre las consultas y claves escalados por la raíz cuadrada de la dimensión. Esta técnica mejora la estabilidad numérica durante el entrenamiento.
Multi-Head Attention
Introducida por Vaswani et al. (2017), la atención multi-cabeza permite que el modelo aprenda diferentes representaciones desde múltiples subespacios proyectados. Cada cabeza realiza su propia atención y las salidas se concatenan y proyectan nuevamente. Esto mejora la capacidad del modelo para capturar diferentes tipos de relaciones semánticas simultáneamente.
Donde cada cabeza es:
Masked (Causal) Self-Attention
Fundamental para tareas autoregresivas como generación de texto, este mecanismo introduce una máscara triangular inferior en la matriz de atención para bloquear el acceso a tokens futuros durante el entrenamiento. Esto garantiza que el modelo sólo use información pasada o presente.
Sliding Window Attention
Este método reduce la complejidad computacional limitando la atención a una ventana fija alrededor de cada token. Es ampliamente utilizado en modelos como Longformer (Beltagy et al., 2020), permitiendo manejar secuencias muy largas.
Dilated Attention
Introduce saltos entre los tokens atendidos, permitiendo que cada token acceda a información no adyacente, aumentando el alcance sin incrementar la carga computacional. Es una técnica usada en Sparse Transformer.
Relative Positional Encoding
A diferencia de las codificaciones absolutas, las posiciones relativas permiten al modelo enfocarse en relaciones espaciales más informativas. Fue incorporado en Transformer-XL y mejoró la generalización y el modelado de contexto en tareas como lenguaje continuo.
Tabla de Modelos de Self-Attention
| Modelo | Empresa/Institución | Uso Principal | Fecha de Publicación |
|---|---|---|---|
| Scaled Dot-Product | Base de Transformer, traducción | Junio 2017 | |
| Multi-Head Attention | Captura de múltiples relaciones | Junio 2017 | |
| Causal Self-Attention | Generación de texto (GPT-like) | Junio 2017 | |
| Sliding Window Attention | Hugging Face (Longformer) | Secuencias largas | 2020 |
| Dilated Attention | OpenAI (Sparse Transformer) | Eficiencia en secuencias largas | 2019 |
Frameworks y Herramientas para Self-Attention
| Framework | Uso Principal | Lenguaje |
|---|---|---|
| HuggingFace | Modelos preentrenados (BERT, GPT, T5, etc) | Python |
| PyTorch | Implementación personalizada desde cero | Python |
| TensorFlow | Modelado a nivel empresarial, Keras support | Python |
| NumPy | Simulación numérica y prototipado | Python |
| Matplotlib | Visualización de matrices y flujos | Python |
| Streamlit | Interfaces interactivas para prototipos | Python |
Transformers (Hugging Face)
La biblioteca Transformers de Hugging Face es la herramienta más popular para trabajar con modelos basados en self-attention. Ofrece implementaciones preentrenadas de modelos como BERT, GPT, y T5, con soporte para PyTorch y TensorFlow.
PyTorch
PyTorch es ideal para implementar self-attention desde cero debido a su flexibilidad y soporte para tensores. Es ampliamente utilizado en investigaciones y prototipos.
TensorFlow
TensorFlow ofrece robustez para aplicaciones empresariales, con soporte para modelos Transformer y optimizaciones como XLA para acelerar el entrenamiento.
NumPy y Matplotlib
NumPy se utiliza para cálculos matriciales en implementaciones desde cero, mientras que Matplotlib es útil para visualizar matrices de atención y embeddings.
Streamlit
Streamlit permite crear aplicaciones web interactivas para visualizar el comportamiento de self-attention, ideal para demostraciones y prototipos ligeros.
🧠 ¿En qué orden ocurre el self-attention en un Transformer?
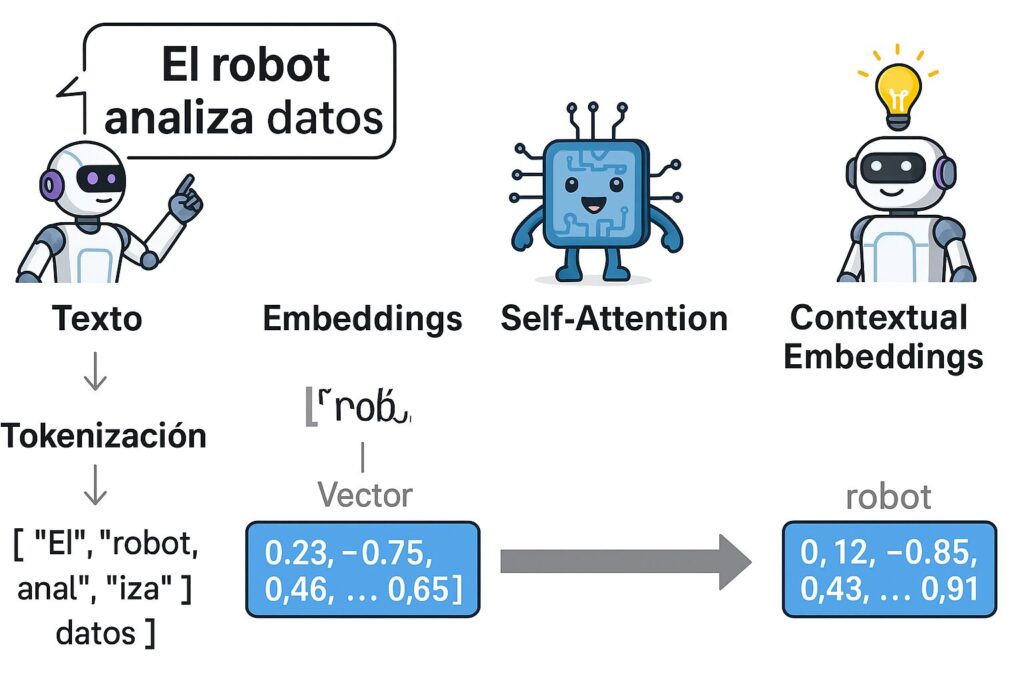
🧩 1. Tokenización
Convierte el texto en unidades básicas llamadas tokens (pueden ser palabras, subpalabras o caracteres).
Ejemplo:
Texto:
"El robot analiza datos"
Tokens:["El", "robot", "anal", "iza", "datos"]
🔢 2. Embeddings
Cada token se convierte en un vector numérico (llamado embedding), que contiene información semántica.
Este vector tiene muchas dimensiones (por ejemplo, 768 en BERT).
Ejemplo:
"robot"→[0.12, -0.85, 0.43, ..., 0.91]
(esto es lo que se llama un embedding)
🧲 3. Self-Attention
Ahora que cada token es un vector, el mecanismo de self-attention trabaja sobre esos vectores para calcular cómo cada token debe “atender” a los otros.
🔁 Esto genera una nueva representación de cada token, donde su vector incluye información contextualizada del resto de la frase.
⚙️ Resumen del flujo exacto:
Texto
↓
Tokenización
↓
Embeddings (vectores de entrada)
↓
Self-Attention (se calcula sobre los embeddings)
↓
Embeddings contextualizados (salida del encoder)
🧠 ¿Por qué no se aplica self-attention sobre los tokens directamente?
Porque los tokens son símbolos (como “robot”, “anal”, “iza”) — no se puede hacer matemática sobre palabras directamente.
Se necesita primero convertirlos en vectores (embeddings) para poder aplicar operaciones como producto punto, softmax, etc.
Implementación Práctica de Self-Attention
Tokenización y Embeddings
Antes de aplicar self-attention, el texto debe tokenizarse y convertirse en embeddings. La tokenización divide el texto en unidades (tokens), y los embeddings convierten estos tokens en vectores numéricos que capturan su significado semántico. Por ejemplo, para la frase “Life is short”:
- Tokens: [“Life”, “is”, “short”]
- Embeddings: Vectores de dimensión dmodel d_{\text{model}} dmodel (e.g., 768 para BERT).
El siguiente código, ejecutable en Google Colab, muestra cómo tokenizar y generar embeddings usando Hugging Face:
from transformers import BertTokenizer, BertModel
import torch
# Cargar tokenizador y modelo
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# Texto de ejemplo
text = "Los robots estan realizando nuevos esquemas de automatización"
inputs = tokenizer(text, return_tensors="pt")
# Obtener embeddings
with torch.no_grad():
outputs = model(**inputs)
embeddings = outputs.last_hidden_state
print("Forma de los embeddings:", embeddings.shape) Resultado del código
Forma de los embeddings: torch.Size([1, 19, 768])Mini App con Streamlit
Streamlit permite crear una aplicación interactiva para visualizar el proceso de self-attention. El siguiente código crea una app que muestra los embeddings y la matriz de atención:
import streamlit as st
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from transformers import BertTokenizer, BertModel
import torch
st.title("Visualización de Self-Attention")
# Entrada de texto
text = st.text_input("Ingrese una frase:", "Life is short")
# Tokenización y embeddings
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
inputs = tokenizer(text, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
embeddings = outputs.last_hidden_state[0].numpy()
# Simulación de atención (simplificada)
d_k = embeddings.shape[-1]
Q = embeddings @ np.random.randn(d_k, d_k)
K = embeddings @ np.random.randn(d_k, d_k)
V = embeddings @ np.random.randn(d_k, d_k)
scores = np.matmul(Q, K.T) / np.sqrt(d_k)
attention_weights = np.exp(scores) / np.sum(np.exp(scores), axis=-1, keepdims=True)
# Visualización
fig, ax = plt.subplots()
sns.heatmap(attention_weights, annot=True, cmap='Blues', ax=ax)
ax.set_title("Matriz de Atención")
ax.set_xlabel("Keys")
ax.set_ylabel("Queries")
st.pyplot(fig)Para ejecutar esta app, guarda el código en un archivo app.py y ejecuta streamlit run app.py en un entorno local con Streamlit instalado.
Visualización de Self-Attention
# app_self_attention.py
import streamlit as st
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
st.title("Visualización de Self-Attention")
# Inputs
seq_len = st.slider("Tamaño de la secuencia", 2, 10, 5)
dim = st.slider("Dimensión de embeddings", 2, 8, 4)
# Random embeddings
X = np.random.rand(seq_len, dim)
W_q, W_k, W_v = np.random.rand(dim, dim), np.random.rand(dim, dim), np.random.rand(dim, dim)
Q, K, V = X @ W_q, X @ W_k, X @ W_v
# Cálculo de atención
scores = Q @ K.T / np.sqrt(K.shape[1])
weights = np.exp(scores) / np.sum(np.exp(scores), axis=1, keepdims=True)
output = weights @ V
# Visualización
fig, ax = plt.subplots()
sns.heatmap(weights, annot=True, cmap="YlGnBu", ax=ax)
ax.set_title("Matriz de atención")
st.pyplot(fig)Salida del programa
Aplicaciones Prácticas de Self-Attention
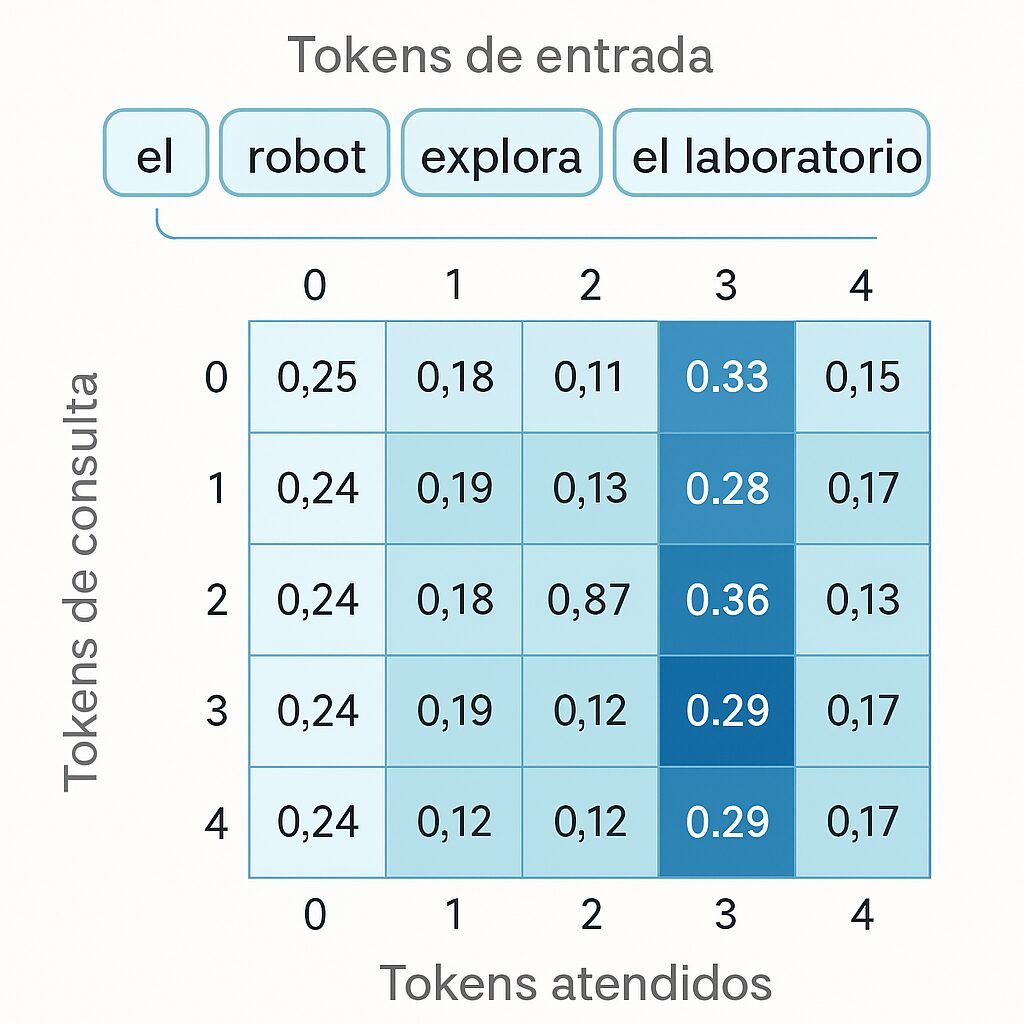
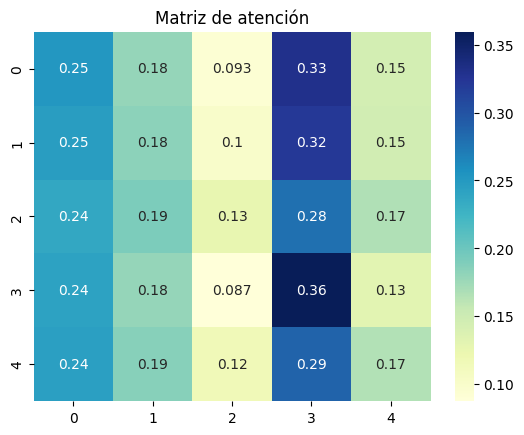
📊 ¿Qué es una matriz de atención?
Una matriz de atención muestra cuánta atención presta cada token de una secuencia a los demás.
- Es una matriz 5×5, lo que indica que la secuencia tiene 5 tokens.
- Cada fila representa un token que consulta (Query).
- Cada columna representa un token al que se atiende (Key).
- Los valores (entre 0 y 1) indican cuánta atención se asigna, y la suma por fila es 1 (softmax).
🧠 Cómo leerla (fila por fila):
Supón que tus tokens son:
[“el”, “robot”, “inspecciona”, “el”, “laboratorio”]
- Fila 0 (token “el”):
- Mira mucho a posición 3 (valor 0.33) → otro “el”, puede ser relevante por repetición.
- Mira poco a la posición 2 (“inspecciona”) → valor 0.093.
- Distribuye atención entre los demás.
- Fila 3 (token “el”):
- Tiene el mayor valor en la posición 3 (0.36) → esto indica que ese “el” se concentra mucho en sí mismo (autoatención).
- Valores menores en otras posiciones.
🎯 ¿Qué te dice esta matriz?
- Contextualización: Muestra cómo cada token se ve afectado por los demás.
- Relaciones semánticas: Si un token presta mucha atención a otro, significa que su significado depende en parte de él.
- Interpretabilidad: Puedes usar esta matriz para explicar qué está entendiendo el modelo.
🧪 ¿Y qué viene después?
Esta matriz se multiplica por la matriz V (Value) para generar los nuevos embeddings contextualizados.
Self-attention es esencial en aplicaciones empresariales de NLP, incluyendo:
- Traducción Automática: Modelos como T5 y MarianMT utilizan self-attention para traducir texto con alta precisión.
- Generación de Texto: GPT-3 y GPT-4 emplean causal self-attention para generar texto coherente.
- Clasificación de Sentimientos: BERT usa self-attention para capturar el contexto en análisis de sentimientos.
- Sistemas de Recomendación: Modelos como BERT4Rec integran self-attention para recomendaciones personalizadas.
Desafíos y Optimizaciones
Desafíos
- Complejidad Computacional: La atención cuadrática puede ser prohibitiva para secuencias muy largas.
- Uso de Memoria: Las matrices de atención requieren grandes cantidades de memoria.
- Interpretabilidad: Las matrices de atención pueden ser difíciles de interpretar sin herramientas de visualización.
Optimizaciones
- FlashAttention: Reduce el uso de memoria al optimizar los cálculos de atención (Dao et al., 2022).
- Sparse Attention: Modelos como Longformer y Sparse Transformer reducen la complejidad usando patrones de atención dispersos.
- Quantización: Reduce el tamaño de los modelos para implementaciones en dispositivos con recursos limitados.
Consejos para Proyectos Empresariales
- Selección del Modelo: Usa modelos preentrenados de Hugging Face y ajusta (fine-tune) con datos específicos de la empresa.
- Optimización: Implementa FlashAttention o modelos como Longformer para manejar secuencias largas.
- Visualización: Usa Streamlit para crear dashboards interactivos que expliquen el comportamiento del modelo a stakeholders.
- Escalabilidad: Considera el uso de APIs como la de xAI (https://x.ai/api) para integrar modelos en producción.
Conclusión
Self-attention es un componente crítico de los modelos de lenguaje modernos, permitiendo capturar relaciones contextuales de manera eficiente y escalable. Con frameworks como Hugging Face, PyTorch y herramientas de visualización como Streamlit, los desarrolladores pueden implementar y experimentar con self-attention en proyectos empresariales. Los ejemplos de código proporcionados, ejecutables en Google Colab, y la mini app de Streamlit ofrecen una base práctica para explorar este mecanismo. Al dominar self-attention, estarás preparado para desarrollar soluciones de NLP innovadoras y efectivas.
Referencias
- Vaswani, A., et al. (2017). Attention is All You Need. arXiv:1706.03762.
- Beltagy, I., et al. (2020). Longformer: The Long-Document Transformer. arXiv:2004.05150.
- Child, R., et al. (2019). Generating Long Sequences with Sparse Transformers. arXiv:1904.10509.
- Dao, T., et al. (2022). FlashAttention: Fast and Memory-Efficient Exact Attention. arXiv:2205.14135.
- Hugging Face. (2023). Transformers Documentation. huggingface.co.
Notas del Autor: Algunos ejemplos de código y visualizaciones son simplificaciones para fines educativos. Las implementaciones reales en entornos empresariales pueden requerir optimizaciones adicionales, que se encuentran en investigación activa por parte de la comunidad científica (por ejemplo, nuevas variantes de atención eficiente). Se recomienda experimentar con los códigos proporcionados y consultar la documentación oficial de los frameworks para aplicaciones en producción.


コメント