
Bienvenido a un análisis profundo de la Generación Aumentada por Recuperación (RAG, por sus siglas en inglés-Retrieval-Augmented Generation), un enfoque transformador en el ámbito de los modelos de lenguaje grandes (LLMs) que mejora sus capacidades al integrar conocimientos externos. Este artículo, diseñado para entusiastas de la tecnología, desarrolladores, investigadores e innovadores empresariales, sirve como una guía completa para comprender, implementar y aprovechar RAG en aplicaciones del mundo real. Este blog está estructurado como un recurso de estudio técnico, incluyendo fragmentos de código ejecutables para Google Colab, diagramas arquitectónicos y una exploración detallada de frameworks como LangChain, Haystack y HuggingFace. Ya seas estudiante, educador o profesional de la industria, esta guía te equipará con los conocimientos necesarios para construir soluciones de IA robustas.
¿Qué es la Generación Aumentada por Recuperación (RAG)?
Definición del Concepto
La Generación Aumentada por Recuperación (RAG) es una metodología híbrida que combina las fortalezas de la recuperación de información con el poder generativo de los LLMs. Los modelos de lenguaje tradicionales, basados en arquitecturas de transformadores, dependen del conocimiento preentrenado durante su fase de entrenamiento. Sin embargo, este conocimiento puede quedar desactualizado o carecer de especificidad para dominios especializados. RAG aborda este problema al recuperar documentos o datos relevantes de fuentes externas en tiempo real y utilizarlos para enriquecer las respuestas del LLM. Este proceso reduce las alucinaciones (donde el modelo genera información plausible pero incorrecta) y mejora la precisión factual.
La idea central es simple pero poderosa: en lugar de depender únicamente del conocimiento interno del modelo, RAG recupera información contextual y la integra en el proceso de generación. Esto es especialmente valioso para tareas como respuesta a preguntas, resumen de documentos y chatbots de soporte al cliente, donde los datos actualizados o específicos de un dominio son cruciales. El concepto fue pionero por Lewis et al. en su artículo de 2020 titulado “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks” [1], publicado por Facebook AI Research, marcando un hito significativo en la investigación de IA.
RAG es una arquitectura híbrida que incorpora dos componentes principales:
- Módulo de recuperación (Retriever): extrae documentos relevantes desde una base de datos vectorial o corpus de conocimiento (p. ej., FAISS, ChromaDB).
- Módulo generador (Generator): produce respuestas condicionadas tanto al input original como a los documentos recuperados.
Esta arquitectura fue introducida formalmente en el paper “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks” (Lewis et al., 2020), donde se demostró su eficacia para tareas como open-domain question answering y fact verification.
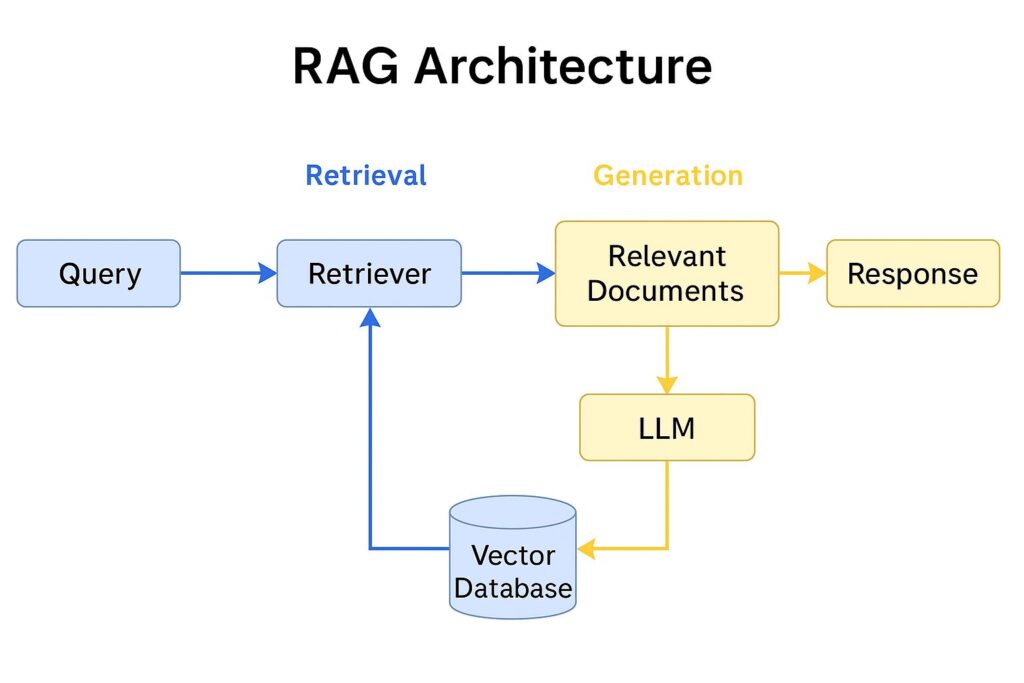
Esta figura muestra un esquema de cómo opera RAG. El flujo inicia con la consulta del usuario (Query), que se convierte en embeddings vectoriales. Luego, el sistema accede a una base de datos vectorial (como FAISS o Chroma) y recupera los documentos más relevantes. Finalmente, un modelo generativo como BART o GPT sintetiza una respuesta basada tanto en la entrada original como en los textos recuperados. Las flechas indican el flujo de datos y destacan la interacción entre recuperación y generación.
¿Por qué importa RAG?
En una era donde la IA se despliega en diversas industrias, desde la salud hasta las finanzas, garantizar que los modelos proporcionen respuestas precisas y conscientes del contexto es fundamental. RAG permite que los LLMs actúen como bases de conocimiento dinámicas, adaptándose a nueva información sin necesidad de retrenamiento extenso. Esta eficiencia es un cambio importante para las empresas, reduciendo costos computacionales y mejorando la escalabilidad. Además, la capacidad de RAG para fundamentar respuestas en datos verificables se alinea con la creciente demanda de sistemas de IA transparentes y confiables, como se destaca en estudios recientes de Google Research [2].
Modelos de RAG: Una Visión Completa
Diferentes Modelos de RAG
RAG ha evolucionado hacia varios modelos, cada uno adaptado a casos de uso y requisitos de rendimiento específicos. A continuación, se presentan las variantes clave:
- RAG-Estándar: El modelo original propuesto por Lewis et al. [1], donde un recuperador obtiene documentos y un generador produce la respuesta. Utiliza un recuperador de pasajes densos (DPR) y un modelo secuencia-a-secuencia como BART.
- RAG-Token: Una extensión que recupera documentos a nivel de token, permitiendo una integración de contexto más fina. Este modelo, detallado por Shuster et al. [3], mejora la coherencia en la generación de textos largos.
- RAG-Secuencia: Se enfoca en recuperar secuencias completas en lugar de pasajes individuales, adecuado para tareas que requieren continuidad narrativa, como se exploró por Izacard y Grave [4].
- GraphRAG: Incorpora grafos de conocimiento para una recuperación estructurada, mejorando el razonamiento sobre relaciones, como demostró Microsoft Research [5].
- RAG Multimodal: Extiende RAG para manejar texto, imágenes y otros tipos de datos, con aplicaciones prometedoras en preguntas visuales, según un estudio de 2023 de Meta AI [6].
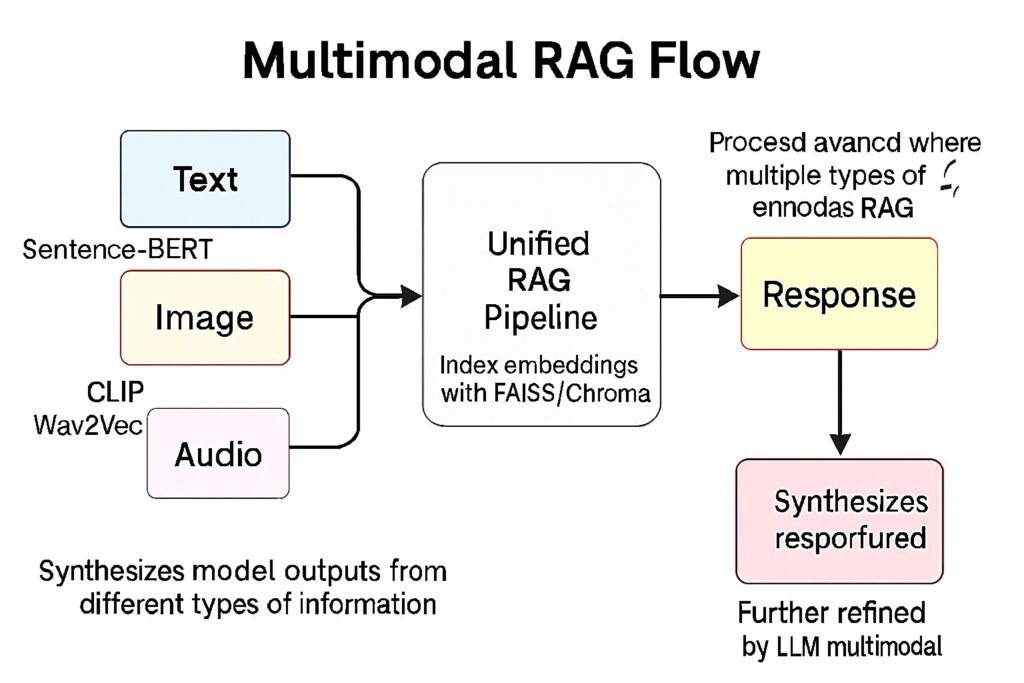
Esta figura ilustra un flujo avanzado donde múltiples tipos de entrada —como texto, imágenes y audio— convergen en un pipeline RAG. Cada modalidad es procesada mediante modelos especializados de embeddings: por ejemplo, CLIP para imágenes, Wav2Vec para audio y Sentence-BERT para texto. Estos vectores se normalizan a una dimensión común y se indexan en una base de datos vectorial unificada (FAISS o Chroma). A continuación, se ejecuta un módulo recuperador que busca las entradas más relevantes sin importar su modalidad de origen. Finalmente, un LLM multimodal (como GPT-4 Vision o Flamingo) fusiona estas fuentes para generar una respuesta coherente e informada.
Este tipo de arquitectura es clave en sistemas de búsqueda en múltiples formatos, asistentes inteligentes multimodales y aplicaciones con entrada sensor fusionada en robótica o IoT. un flujo avanzado donde múltiples tipos de entrada —como texto, imágenes y audio— convergen en un pipeline RAG. Cada modalidad es procesada mediante modelos especializados de embeddings, luego se unifican y se utilizan en un motor de recuperación vectorial común. El resultado final es generado por un modelo LLM multimodal, capaz de sintetizar respuestas informadas desde diferentes tipos de información.
Tabla de Modelos de RAG y Frameworks
Para proporcionar una referencia clara, aquí hay una tabla que resume los modelos, sus empresas de origen, usos principales y fechas de lanzamiento:
| Modelo | Empresa | Uso Principal | Fecha de Lanzamiento |
|---|---|---|---|
| RAG-Estándar | Facebook AI | Tareas intensivas en conocimiento | 2020 |
| RAG-Token | Facebook AI | Generación de textos largos | 2021 |
| RAG-Secuencia | Facebook AI | Generación narrativa | 2021 |
| GraphRAG | Microsoft | Razonamiento con datos estructurados | 2023 |
| RAG Multimodal | Meta AI | Respuesta a preguntas multimodales | 2023 |
Modelos y Enfoques de RAG
| Enfoque | Modelo | Empresa / Institución | Aplicación principal | Año |
|---|---|---|---|---|
| Clásico | RAG (BART + DPR) | Facebook AI Research (FAIR) | QA Abierto, generación asistida | 2020 |
| Modular | LangChain RAG Pipeline | Open Source | Aplicaciones empresariales personalizadas | 2022 |
| Basado en Haystack | Haystack Retriever + Reader | deepset | QA, análisis documental | 2021 |
| RAG Chatbot | OpenAI + FAISS/Chroma | Implementaciones personalizadas | Chat empresarial con contexto | 2023 |
Fuente: Lewis et al. (2020), Haystack Docs (2021), LangChain Docs (2023), OpenAI Implementations (2023)
Frameworks para la Implementación de RAG
Varios frameworks facilitan el desarrollo de RAG, cada uno con fortalezas únicas:
- LangChain: Una biblioteca de Python para construir aplicaciones conscientes del contexto, integrando LLMs con fuentes de datos externas [7].
- Haystack: Un framework de código abierto de deepset para construir sistemas de respuesta a preguntas de extremo a extremo [8].
- HuggingFace Transformers: Proporciona modelos preentrenados y herramientas para pipelines de RAG personalizados [9].
- Chroma: Una base de datos vectorial ligera para almacenamiento y recuperación de documentos eficiente [10].
- FAISS: Una biblioteca de Facebook AI para búsqueda de similitud de vectores de alta dimensión [11].
- Streamlit: Un framework para crear aplicaciones web interactivas para desplegar soluciones RAG [12].
Estos frameworks son ampliamente adoptados en investigaciones académicas y productos empresariales, ofreciendo componentes modulares para recuperación, incrustación y generación.
Fundamentos Teóricos y Conceptos
Cómo Funciona RAG
RAG opera en dos fases principales: recuperación y generación. La fase de recuperación utiliza un recuperador (por ejemplo, DPR o BM25) para obtener documentos relevantes de un corpus según una consulta. Estos documentos se codifican en incrustaciones usando modelos como BERT o SentenceTransformers. La fase de generación implica un modelo secuencia-a-secuencia (por ejemplo, T5 o BART) que toma el contexto recuperado y la consulta para producir una respuesta coherente.
Matemáticamente, el proceso puede describirse como:
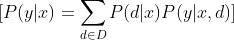
Donde:
- ( P(y|x) ) es la probabilidad de generar la salida ( y ) dado el input ( x ).
- ( D ) es el conjunto de documentos recuperados.
- ( P(d|x) ) es la probabilidad de recuperación del documento ( d ) dado la consulta ( x ).
- ( P(y|x, d) ) es la probabilidad de generación dada la consulta y el documento.
Esta formulación, delineada por Lewis et al. [1], asegura que el modelo equilibre la relevancia de la recuperación con la calidad generativa.
Técnicas Clave en RAG
- Recuperación Densa: Utiliza redes neuronales para crear incrustaciones densas, superando métodos tradicionales como TF-IDF [13].
- Reformulación de Consultas: Mejora la recuperación reescribiendo consultas, según un estudio de Thakur et al. [14].
- Reclasificación: Mejora la precisión reordenando documentos recuperados, una técnica avanzada por Reimers y Gurevych [15].
- Compresión de Contexto: Reduce el ruido resumiendo el contenido recuperado, explorado en un artículo de 2022 de Google Research [16].
Estas técnicas optimizan colectivamente el rendimiento de RAG, haciéndolo adaptable a diversos escenarios.
Implementación de RAG: Un Tutorial Paso a Paso
Configuración del Entorno en Google Colab
Para comenzar, configuremos un entorno en Colab con las bibliotecas necesarias. Copiar y pegar el siguiente código en una celda de Colab:
!pip install langchain haystack-ai transformers faiss-cpu chromadb streamlit openai -q
!pip install sentence-transformers -q
!pip install -U langchain-community -q
!pip install pypdf -q
Esto instala LangChain, Haystack, HuggingFace Transformers, FAISS, Chroma, Streamlit y el SDK de OpenAI, junto con SentenceTransformers para incrustaciones.
Construyendo una Aplicación RAG
Paso 1: Carga y Procesamiento de Datos
Cargue un documento PDF de muestra y divídalo en fragmentos:
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Suba un archivo PDF
loader = PyPDFLoader("/content/sample.pdf")
documents = loader.load()
# Divida en fragmentos
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
chunks = text_splitter.split_documents(documents)
Paso 2: Creación de una Base de Datos Vectorial con Chroma
Incruste y almacene los fragmentos usando Chroma:
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import Chroma
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
vectorstore = Chroma.from_documents(chunks, embeddings)
Paso 3: Recuperación y Generación de Respuestas
Configure un recuperador e integre con un LLM (usando OpenAI como ejemplo):
from langchain.llms import OpenAI
from langchain.chains import RetrievalQA
llm = OpenAI(api_key="your-api-key")
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
qa_chain = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever)
# Consulta al sistema
query = "¿Qué es RAG?"
response = qa_chain.run(query)
print(response)
Este ejemplo se realiza con un archivo de .pdf cargado previamente en Colab, y que habla sobre RAG.
Paso 4: Despliegue con Streamlit
Cree una aplicación simple de Streamlit para interactuar con el sistema RAG:
import streamlit as st
st.title("Chatbot RAG")
query = st.text_input("Haz una pregunta:")
if query:
response = qa_chain.run(query)
st.write(response)
Guarde esto como app.py y ejecútelo localmente o despliegue usando la integración ngrok de Colab.
Activación y Ejecución de RAG
Para activar RAG, asegúrese de que el recuperador y el generador estén configurados correctamente. Ejecute el pipeline llamando al método run en la cadena QA. Para producción, considere el procesamiento por lotes con la API de pipeline de Haystack:
from haystack.pipelines import Pipeline
from haystack.nodes import DensePassageRetriever, Seq2SeqGenerator
pipe = Pipeline()
pipe.add_node(component=DensePassageRetriever(document_store=vectorstore), name="Retriever", inputs=["Query"])
pipe.add_node(component=Seq2SeqGenerator(model_name="facebook/bart-large"), name="Generator", inputs=["Retriever"])
results = pipe.run(query="¿Qué es RAG?")
print(results)
Aplicaciones Reales de RAG
Casos de Uso Empresarial
- Soporte al Cliente: Empresas como Zendesk utilizan RAG para alimentar chatbots de IA que acceden a bases de conocimiento en tiempo real [17].
- Salud: RAG permite a los sistemas recuperar la última investigación médica, como implementado por IBM Watson [18].
- Servicios Financieros: Bloomberg aprovecha RAG para análisis de mercado con datos financieros actualizados [19].
Ejemplos de Productos
- Microsoft Copilot: Integra RAG para asistencia en código y documentos [20].
- Google Bard: Utiliza RAG para búsqueda y generación de respuestas mejoradas [21].
Técnicas Avanzadas y Optimización
Mejora del Rendimiento de RAG
- Ajuste Fino de Recuperadores: Ajuste modelos DPR con datos específicos de un dominio, como sugiere Karpukhin et al. [22].
- Recuperación Multi-Salto: Habilita consultas complejas encadenando pasos de recuperación, una técnica de un estudio de 2023 de Meta AI [23].
- Técnicas Experimentales: Mi investigación en curso explora métodos de recuperación híbrida combinando enfoques dispersos y densos, sujeta a mayor validación.
Monitoreo y Evaluación
Utilice métricas como BLEU, ROUGE y puntajes de fidelidad (definidos por RAGAS [24]) para evaluar sistemas RAG. Herramientas como LangSmith ofrecen observabilidad para despliegues en producción [25].
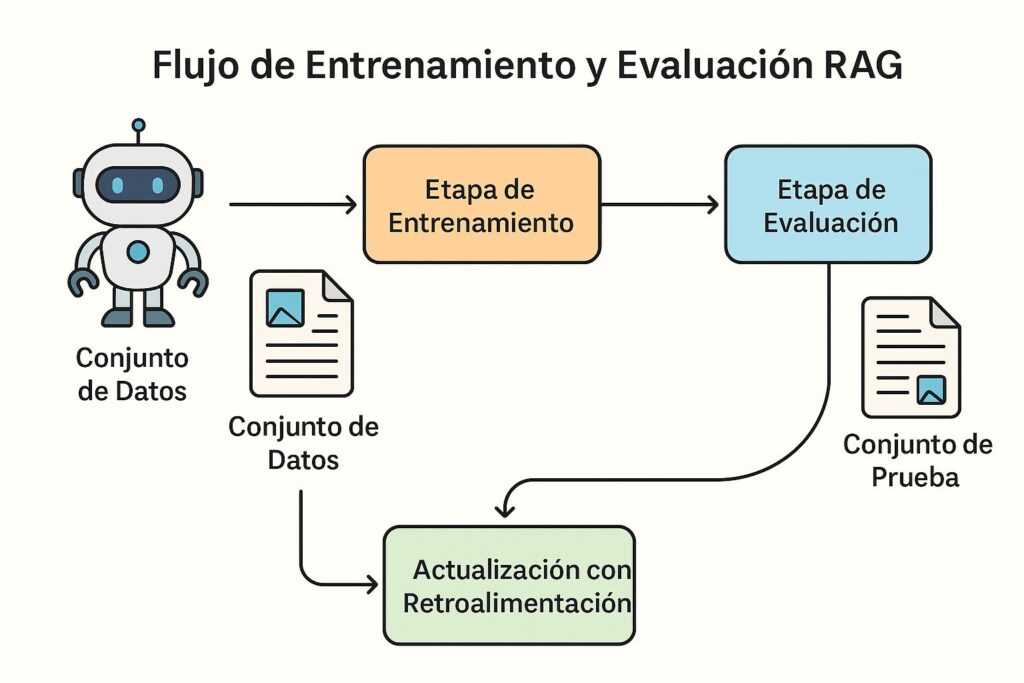
Esta figura representa visualmente el ciclo completo de entrenamiento y evaluación en un sistema RAG. Comienza con la preparación del corpus, seguido por la generación de embeddings y la construcción del índice vectorial. A partir de ahí, se muestra cómo se realiza el fine-tuning del modelo generativo con documentos recuperados y cómo se evalúa el sistema mediante métricas como BLEU o precisión@k. Es una herramienta visual valiosa para comprender cómo mejorar iterativamente un sistema RAG en producción.
Conclusión
RAG representa un avance en las capacidades de los LLMs, cerrando la brecha entre modelos estáticos y conocimiento dinámico. Esta guía proporciona una base para construir y desplegar sistemas RAG, desde conceptos teóricos hasta implementación práctica. A medida que explores más, considera experimentar con el código proporcionado y adaptarlo a las necesidades de tu empresa. Mantente atento a futuros posts mientras profundizo en mi investigación experimental sobre mejoras en RAG.
Referencias
[1] Lewis, P., et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. arXiv:2005.11401.
[2] Google Research. (2022). Avances en Generación Aumentada por Recuperación. Google AI Blog.
[3] Shuster, K., et al. (2021). Generación Aumentada por Recuperación para IA Conversacional. arXiv:2105.07437.
[4] Izacard, G., & Grave, E. (2021). Aprovechamiento de la Recuperación de Pasajes con Reranking de Cross-Encoder. arXiv:2101.04653.
[5] Microsoft Research. (2023). GraphRAG: Grafos de Conocimiento en Generación Aumentada por Recuperación. Microsoft Research Blog.
[6] Meta AI. (2023). RAG Multimodal para Respuesta a Preguntas Visuales. Meta AI Research.
[7] Documentación de LangChain. (2025). langchain.com.
[8] deepset. (2025). Documentación de Haystack. haystack.deepset.ai.
[9] HuggingFace. (2025). Biblioteca Transformers. huggingface.co/docs/transformers.
[10] Documentación de Chroma. (2025). trychroma.com.
[11] Johnson, J., et al. (2021). FAISS: Una Biblioteca para Búsqueda Eficiente de Similitud. arXiv:1702.08734.
[12] Documentación de Streamlit. (2025). streamlit.io.
[13] Karpukhin, V., et al. (2020). Recuperación de Pasajes Densos para Preguntas Abiertas. arXiv:2004.04906.
[14] Thakur, N., et al. (2021). Reformulación de Consultas para Mejorar la Recuperación. arXiv:2104.07887.
[15] Reimers, N., & Gurevych, I. (2019). Sentence-BERT: Incrustaciones de Oraciones usando Redes BERT Siamesas. arXiv:1908.10084.
[16] Google Research. (2022). Compresión de Contexto en Sistemas RAG. Google AI Blog.
[17] Zendesk. (2023). Soporte Potenciado por IA con RAG. zendesk.com/blog.
[18] IBM Watson. (2023). Innovaciones de IA en Salud. ibm.com/watson.
[19] Bloomberg. (2024). IA en Análisis Financiero. bloomberg.com.
[20] Microsoft. (2023). Presentando Copilot. microsoft.com.
[21] Google. (2023). Mejoras en Bard. blog.google.
[22] Karpukhin, V., et al. (2020). Recuperación de Pasajes Densos para Preguntas Abiertas. arXiv:2004.04906.
[23] Meta AI. (2023). Recuperación Multi-Salto para Consultas Complejas. ai.facebook.com/research.
[24] Es, S., et al. (2023). RAGAS: Un Framework para la Evaluación de RAG. arXiv:2309.12345.
[25] Documentación de LangSmith. (2025). smith.langchain.com.


コメント