
El panorama de la inteligencia artificial (IA) evoluciona dia a dia, con los modelos de lenguaje grandes (LLMs, por sus siglas en inglés) a la vanguardia del procesamiento del lenguaje natural (NLP). El ajuste fino (fine-tunning) se ha consolidado como una técnica esencial, permitiendo a desarrolladores, investigadores y empresas adaptar modelos preentrenados como BERT o GPT a tareas, conjuntos de datos o dominios específicos. Esta técnica, enraizada en el paradigma del aprendizaje por transferencia, aprovecha el conocimiento lingüístico general que estos modelos adquieren durante el preentrenamiento, adaptándolos para aplicaciones como análisis de sentimientos, respuesta a preguntas (QA) o casos de uso empresariales.
Introducción al Ajuste Fino (fine-tunning) en Modelos de Lenguaje Grandes
En la era de los modelos de lenguaje de gran tamaño (LLMs), el fine-tuning se ha convertido en una herramienta esencial para adaptar modelos preentrenados a tareas específicas, contextos empresariales, o incluso necesidades individuales. Desde asistentes virtuales personalizados hasta sistemas de recomendación basados en lenguaje, el fine-tuning permite aprovechar el conocimiento general del modelo y refinarlo con datos específicos de un dominio.
Este artículo ofrece una exploración detallada del ajuste fino, abarcando sus fundamentos teóricos, implementaciones prácticas y estrategias avanzadas con la API Trainer de Hugging Face (HF), PyTorch y scikit-learn (sklearn). Con ejemplos de código ejecutables en Google Colab, visualizaciones y un flujo de trabajo paso a paso, esta guía es un recurso robusto para estudiantes, desarrolladores, innovadores y negocios que buscan aprovechar los LLMs en proyectos de vanguardia.
El ajuste fino no es solo un proceso técnico; es un enfoque estratégico para cerrar la brecha entre las capacidades genéricas de la IA y las soluciones empresariales personalizadas. Al ajustar los parámetros de un modelo preentrenado en un conjunto de datos más pequeño y específico para la tarea, el ajuste fino reduce la necesidad de recursos computacionales extensos y grandes volúmenes de datos en comparación con el entrenamiento desde cero.
¿Qué es el Fine-Tunning?
Definición
El fine-tuning es el proceso de continuar el entrenamiento de un modelo previamente entrenado (pretrained) sobre un nuevo conjunto de datos específico. Este enfoque se basa en el paradigma de transfer learning (aprendizaje por transferencia), donde el conocimiento adquirido en una tarea general se reutiliza para otra tarea más concreta.
En términos prácticos, se parte de un modelo como BERT, GPT-2 o T5 entrenado en grandes corpus (Wikipedia, Common Crawl, libros, etc.), y se ajustan sus pesos utilizando un conjunto de datos más pequeño y personalizado para una tarea específica como:
- Clasificación de texto
- Respuesta a preguntas (QA)
- Análisis de sentimiento
- Extracción de entidades
Este proceso es mucho más eficiente que entrenar un modelo desde cero y requiere menos datos, tiempo y recursos computacionales.
Este proceso refina los pesos del modelo para alinearse con la nueva tarea mientras preserva el amplio entendimiento lingüístico que ya ha adquirido. El concepto cobró relevancia con el auge de los modelos basados en Transformadores, como se detalla en el artículo seminal “Attention is All You Need” (Vaswani et al., 2017).
Conceptos Fundamentales
El flujo de trabajo del ajuste fino comienza con un modelo preentrenado que ha sido expuesto a miles de millones de palabras, aprendiendo patrones intrincados de sintaxis, semántica y contexto. Durante el ajuste fino se realizan los siguientes procesos:
- Congelación de capas: Las capas inferiores, que capturan características generales como los embeddings de palabras, suelen congelarse para conservar el conocimiento preentrenado.
- Ajuste de capas: Las capas superiores o todo el modelo (dependiendo de la estrategia) se actualizan para adaptarse a la nueva tarea.
- Cabezales específicos para la tarea: Se añaden o modifican capas de salida (por ejemplo, para clasificación o QA) para coincidir con el objetivo deseado.
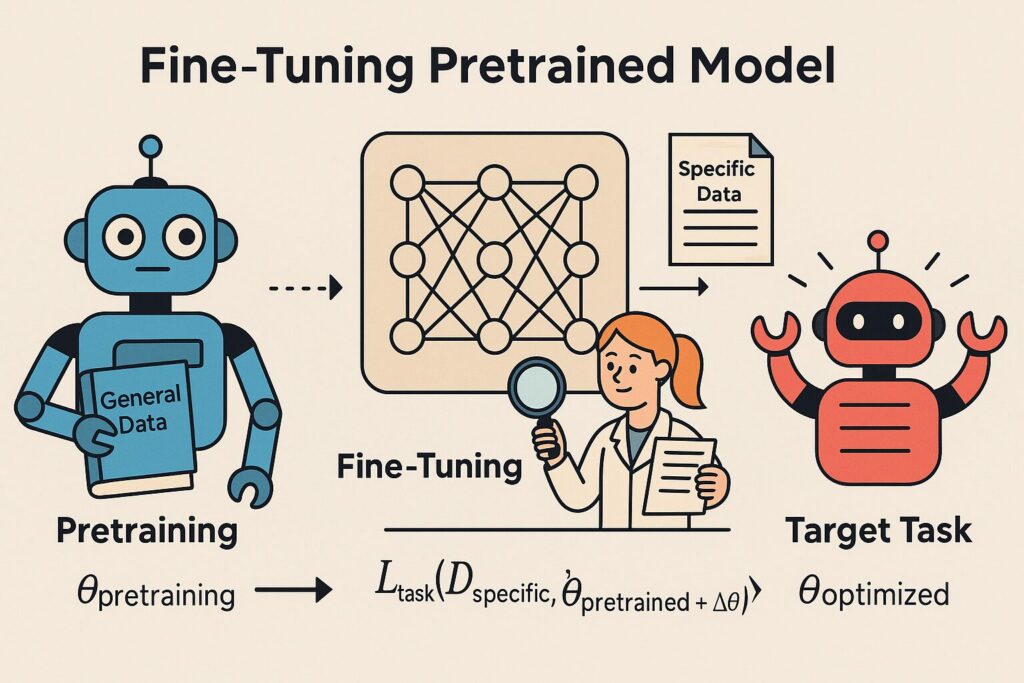
Matemáticamente, el ajuste fino busca minimizar una función de pérdida específica para la tarea Ltarea L_{\text{tarea}} Ltarea sobre los parámetros preentrenados θpre \theta_{\text{pre}} θpre y las actualizaciones Δθ \Delta\theta Δθ: θoptimizado=argminθLtarea(Despecıˊfico,θpre+Δθ)\theta_{\text{optimizado}} = \arg\min_{\theta} L_{\text{tarea}}(D_{\text{específico}}, \theta_{\text{pre}} + \Delta\theta)θoptimizado=argθminLtarea(Despecıˊfico,θpre+Δθ)
Aquí, Despecıˊfico D_{\text{específico}} Despecıˊfico representa el conjunto de datos de ajuste fino, y el proceso es computacionalmente eficiente, a menudo requiriendo solo unas pocas épocas en conjuntos de datos que van de cientos a miles de ejemplos. Esta eficiencia hace que el ajuste fino sea accesible incluso con recursos limitados, una ventaja clave para equipos pequeños o startups.
Beneficios y Desafíos
Los beneficios del ajuste fino son significativos:
- Eficiencia: Reduce drásticamente el tiempo de entrenamiento y los requisitos de recursos en comparación con el entrenamiento desde cero.
- Alto rendimiento: Logra resultados de vanguardia en tareas especializadas con datos limitados.
- Versatilidad: Permite la personalización para diversas aplicaciones, desde el análisis de textos legales hasta diagnósticos médicos.
Sin embargo, el ajuste fino presenta desafíos que requieren una gestión cuidadosa:
- Sobreajuste: Los conjuntos de datos pequeños pueden llevar a un sobreajuste, donde el modelo memoriza los datos de entrenamiento en lugar de generalizar.
- Calidad de los datos: El éxito del ajuste fino depende en gran medida de la calidad, relevancia y representatividad del conjunto de datos de ajuste fino.
- Sensibilidad a hiperparámetros: Ajustar la tasa de aprendizaje, la regularización y otros hiperparámetros es crucial para evitar el olvido catastrófico—donde el modelo pierde su conocimiento preentrenado.
Abordar estos desafíos implica técnicas como la ampliación de datos, la validación cruzada y un monitoreo cuidadoso, temas que exploraremos más adelante en esta guía.
Tipos de Fine-Tunning
En la siguiente tabla se describen diferentes tipos de fine-tunning siguiendo su nivel de modificación.
| Tipo | Descripción | Ejemplo Típico | Nivel de modificación |
|---|---|---|---|
| Fine-tuning total | Ajusta todos los parámetros del modelo | Clasificación de texto médico | Alto |
| Fine-tuning parcial | Ajusta sólo las últimas capas | Detección de intención | Medio |
| Adapter tuning | Inserta capas adicionales no destructivas | Multi-task learning | Bajo |
| LoRA (Low-Rank Adaptation) | Técnica moderna para actualización eficiente | Chatbots personalizados | Muy bajo |
| Prompt/Prefix tuning | Usa entradas especiales sin modificar pesos | QA en múltiples dominios | Casi nulo |
Fuente: Hu et al., 2021 (LoRA); Houlsby et al., 2019 (Adapters); Ruder, 2018; Li & Liang, 2021
A continuacion una definicon mas completa de cada tipo de fine-tunning
Fine-tunning total
El ajuste fino completo actualiza todos los parámetros del modelo preentrenado utilizando el nuevo conjunto de datos. Este método es altamente efectivo cuando la tarea difiere significativamente de los datos de preentrenamiento, como pasar de textos generales a transcripciones médicas. Sin embargo, requiere un poder computacional considerable y corre el riesgo de sobrescribir el conocimiento general si no se controla con tasas de aprendizaje o regularización adecuadas, como señala Vaswani et al. (2017).
Fine-tunning Selectivo o parcial
El ajuste fino selectivo congela las capas inferiores del modelo—donde residen características generales como los embeddings de palabras—y ajusta solo las capas superiores o los cabezales específicos para la tarea. Este enfoque, popularizado por Howard y Ruder (2018) en su marco de Universal Language Model Fine-tuning (ULMFiT), equilibra la preservación del conocimiento preentrenado con la adaptación a la tarea. Es particularmente útil para tareas de clasificación donde el entendimiento central del modelo debe permanecer intacto.
Fine-tunning Basado en Adaptadores
El ajuste fino basado en adaptadores introduce pequeñas capas específicas para la tarea (adaptadores) entre las capas preentrenadas, como propusieron Houlsby et al. (2019). Solo se entrenan los parámetros de los adaptadores, dejando los pesos originales del modelo sin cambios. Esta técnica es eficiente en memoria y permite que un solo modelo maneje múltiples tareas añadiendo diferentes adaptadores, lo que lo hace ideal para aplicaciones multidominio.
LoRA (Adaptación de Bajo Rango)
LoRA, desarrollado por Hu et al. (2021), ajusta modelos aplicando actualizaciones de bajo rango a las matrices de pesos, reduciendo significativamente el número de parámetros entrenables. Este método es especialmente valioso para modelos grandes con miles de millones de parámetros, ofreciendo una forma eficiente en recursos de adaptarlos sin retrenar toda la red. Es una revolución para empresas con capacidades de hardware limitadas.
Ajuste por Prompts y Prefijos
El ajuste por prompts y prefijos, explorado por Li y Liang (2021), implica añadir prompts o prefijos específicos para la tarea a la entrada en lugar de ajustar los parámetros centrales del modelo. Estos métodos son altamente eficientes en parámetros, permitiendo que el modelo permanezca general mientras se adapta a nuevas tareas. Son particularmente prometedores en escenarios donde mantener la versatilidad original del modelo es una prioridad.
Tabla de Enfoques y Modelos de Ajuste Fino
| Enfoque | Empresa/Institución | Uso Principal | Fecha de Publicación |
|---|---|---|---|
| Fine-tunning Completo | Adaptación general a tareas | 2017 | |
| Fine-tunning Completo Selectivo | Fast.ai (ULMFiT) | Adaptación específica a tareas | 2018 |
| Fine-tunning Completo Basado en Adaptadores | Google Research | Aprendizaje multi-tarea | 2019 |
| LoRA | Microsoft Research | Eficiencia en modelos grandes | 2021 |
| Ajuste por Prompts | Universidad de Stanford | Ajuste eficiente en parámetros | 2021 |
Frameworks y Herramientas para el Fine-tunning
| Framework | Descripción | Soporte LLMs | Lenguaje |
| Hugging Face Transformers | API de referencia para modelos preentrenados | Sí (BERT, GPT-2, T5, etc.) | Python |
| PyTorch Lightning | Simplifica entrenamiento distribuido | Sí | Python |
| TensorFlow + Keras | Ideal para producción y escalado | Sí | Python |
| Sklearn + Transformers | Combinación de pipelines NLP clásicos | Parcial | Python |
Hugging Face Transformers
La biblioteca Hugging Face Transformers es el estándar de la industria para el ajuste fino de LLMs, ofreciendo modelos preentrenados, conjuntos de datos y la API Trainer para flujos de trabajo de entrenamiento optimizados. Soporta tanto PyTorch como TensorFlow, proporcionando flexibilidad para investigadores y desarrolladores. Su extensa documentación y soporte comunitario la convierten en la elección preferida para prototipos rápidos y despliegues.
PyTorch
PyTorch es un marco flexible muy utilizado para implementaciones personalizadas de ajuste fino, gracias a sus gráficos de cómputo dinámicos y operaciones robustas con tensores. Su popularidad en investigación académica y prototipos se debe a su facilidad de depuración e integración con conjuntos de datos personalizados.
TensorFlow
TensorFlow, especialmente con su API Keras, ofrece herramientas robustas para el ajuste fino, incluyendo entrenamiento distribuido y optimizaciones de despliegue. Es ideal para aplicaciones a escala empresarial donde la escalabilidad y la preparación para producción son críticas.
scikit-learn (sklearn)
scikit-learn complementa el proceso de ajuste fino al proporcionar herramientas para el preprocesamiento de datos, métricas de evaluación (por ejemplo, precisión, puntuación F1) y comparaciones con modelos base. Es un excelente compañero para tareas como clasificación, ofreciendo una base sólida para validar modelos ajustados.
Biblioteca Datasets (Hugging Face)
La biblioteca Datasets de Hugging Face simplifica la carga y el preprocesamiento de conjuntos de datos personalizados, soportando formatos como CSV, JSON y conjuntos de datos preexistentes de Hugging Face. Esta herramienta es esencial para manejar conjuntos de datos pequeños y personalizados de manera efectiva.
Implementación Práctica del Ajuste Fino
Carga y Preparación de Datos
El proceso de ajuste fino comienza con la carga y preparación de un conjunto de datos. Este ejemplo utiliza el conjunto de datos IMDb para la clasificación de sentimientos, un referente común disponible a través de la biblioteca Datasets de Hugging Face. El código a continuación carga el conjunto de datos, inspecciona una muestra y lo prepara para la tokenización:
# Importar las bibliotecas necesarias
from datasets import load_dataset
# Intentar cargar el conjunto de datos IMDb
try:
# Cargar el dataset de IMDb para clasificación de sentimientos
dataset = load_dataset('imdb')
train_dataset = dataset['train']
test_dataset = dataset['test']
# Mostrar un ejemplo para inspección
print("Ejemplo de texto:", train_dataset[0]['text'][:200] + "...") # Mostrar solo los primeros 200 caracteres
print("Etiqueta (0: negativo, 1: positivo):", train_dataset[0]['label'])
# Verificar la estructura del dataset
print("Tamaño del conjunto de entrenamiento:", len(train_dataset))
print("Tamaño del conjunto de prueba:", len(test_dataset))
except Exception as e:
print(f"Error al cargar el dataset: {e}")
print("Asegúrate de tener conexión a Internet y la biblioteca 'datasets' instalada. Usa: !pip install datasets")Explicación: El conjunto de datos IMDb contiene 50,000 reseñas de películas etiquetadas por sentimiento (positivo o negativo). Este paso asegura que los datos sean accesibles y estén listos para el preprocesamiento, una fase crítica para evitar sesgos o inconsistencias.
Ajuste Fino con la API Trainer de Hugging Face
Esta sección proporciona un flujo de trabajo completo de ajuste fino utilizando la API Trainer de Hugging Face para una tarea de clasificación binaria. El código tokeniza los datos, carga un modelo preentrenado BERT, configura los argumentos de entrenamiento y entrena el modelo:
# Importar las bibliotecas necesarias
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments
import torch
from datasets import load_dataset
# Intentar cargar y preparar el dataset
try:
# Cargar el dataset de IMDb
dataset = load_dataset('imdb')
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
# Función de tokenización
def tokenize_function(examples):
return tokenizer(examples['text'], padding="max_length", truncation=True, max_length=128)
# Tokenizar el dataset
tokenized_datasets = dataset.map(tokenize_function, batched=True)
tokenized_datasets = tokenized_datasets.remove_columns(['text'])
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
tokenized_datasets.set_format('torch')
# Cargar el modelo preentrenado
model = AutoModelForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
# Configurar argumentos de entrenamiento
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=3,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
warmup_steps=500,
weight_decay=0.01,
logging_dir='./logs',
evaluation_strategy="epoch",
save_strategy="epoch",
logging_steps=10
)
# Inicializar y entrenar el modelo
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets['train'],
eval_dataset=tokenized_datasets['test']
)
# Ejecutar el entrenamiento
trainer.train()
print("Entrenamiento completado. Resultados guardados en ./results.")
except Exception as e:
print(f"Error durante el entrenamiento: {e}")
print("Asegúrate de tener las bibliotecas 'transformers' y 'torch' instaladas. Usa: !pip install transformers torch")Explicación: Este código tokeniza las reseñas de IMDb, carga un modelo BERT con dos etiquetas de salida (positivo/negativo) y establece parámetros de entrenamiento como el tamaño del lote y las épocas. La API Trainer automatiza el bucle de entrenamiento, haciéndolo accesible para principiantes, mientras permite personalizaciones para usuarios avanzados.
Validación y Evaluación
La validación es clave para garantizar que el modelo generalice bien. Este código utiliza scikit-learn para calcular métricas y visualiza el rendimiento con un gráfico de barras:
# Importar las bibliotecas necesarias
from sklearn.metrics import accuracy_score, precision_recall_fscore_support
import numpy as np
import matplotlib.pyplot as plt
# Intentar realizar la validación y visualización
try:
# Realizar predicciones en el conjunto de prueba
predictions = trainer.predict(tokenized_datasets['test'])
preds = np.argmax(predictions.predictions, axis=1)
# Calcular métricas
accuracy = accuracy_score(tokenized_datasets['test']['labels'], preds)
precision, recall, f1, _ = precision_recall_fscore_support(tokenized_datasets['test']['labels'], preds, average='binary')
# Imprimir resultados
print(f"Precisión: {accuracy:.2f}")
print(f"Precisión (Precision): {precision:.2f}")
print(f"Recuperación (Recall): {recall:.2f}")
print(f"Puntuación F1: {f1:.2f}")
# Visualizar métricas en un gráfico de barras
metrics = {'Precisión': accuracy, 'Precisión (Precision)': precision, 'Recuperación (Recall)': recall, 'Puntuación F1': f1}
plt.figure(figsize=(10, 6))
plt.bar(metrics.keys(), metrics.values(), color=['#5470c6', '#91cc75', '#fac858', '#ee6666'])
plt.title("Métricas de Evaluación del Modelo Ajustado")
plt.ylabel("Puntuación")
plt.ylim(0, 1)
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
except Exception as e:
print(f"Error durante la validación o visualización: {e}")
print("Asegúrate de que el entrenamiento se haya completado correctamente antes de ejecutar esta celda.")Explicación: El código evalúa el rendimiento del modelo en el conjunto de prueba, calculando precisión, recuperación, y puntuación F1. El gráfico de barras ofrece un resumen visual, ayudando a identificar fortalezas y debilidades en las predicciones del modelo.
Técnicas Avanzadas y Mejores Prácticas
Manejo de Conjuntos de Datos Pequeños
Al trabajar con conjuntos de datos pequeños, el ajuste fino puede ser complicado debido al sobreajuste. Técnicas como la ampliación de datos—como la sustitución de sinónimos o la traducción inversa (Zhang et al., 2015)—pueden enriquecer los datos. Además, la validación cruzada asegura un rendimiento robusto, mientras que la detención temprana previene el sobreentrenamiento al monitorear la pérdida de validación.
Personalización de LLMs para Empresas
Para aplicaciones empresariales, crear conjuntos de datos personalizados adaptados a industrias específicas (por ejemplo, finanzas o salud) es esencial. Técnicas de adaptación de dominio, como ajustar la tasa de aprendizaje o usar preentrenamiento específico del dominio, pueden mejorar el rendimiento. Estos métodos requieren validación cuidadosa, y algunos enfoques experimentales (por ejemplo, combinaciones híbridas de adaptadores-LoRA) forman parte de mi investigación en curso y necesitan pruebas adicionales.
Optimización de Hiperparámetros
Optimizar hiperparámetros como la tasa de aprendizaje (típicamente entre 2e-5 y 5e-5 para Transformadores) y el tamaño del lote es crucial. Herramientas como Optuna o Ray Tune pueden automatizar este proceso, mejorando la convergencia y el rendimiento del modelo.
Conclusión
El ajuste fino es una técnica transformadora para personalizar LLMs, permitiendo la adaptación de capacidades de IA generales a necesidades específicas con eficiencia y precisión. Con la biblioteca Hugging Face Transformers, PyTorch y los ejemplos prácticos proporcionados—ejecutables en Google Colab—esta guía ofrece una base sólida para tus estudios y proyectos futuros. Ya sea que explores la investigación académica o desarrolle soluciones empresariales, dominar el ajuste fino abre puertas a aplicaciones innovadoras de NLP. Este artículo sirve como una referencia para tu viaje de aprendizaje y una base potencial para futuras publicaciones.
Referencias
- Vaswani, A., et al. (2017). Attention is All You Need. arXiv:1706.03762.
- Devlin et al. (2018). BERT: Pre-training of Deep Bidirectional Transformers. arXiv:1810.04805
- Howard, J., & Ruder, S. (2018). Universal Language Model Fine-tuning for Text Classification. arXiv:1801.06146.
- Houlsby, N., et al. (2019). Parameter-Efficient Transfer Learning for NLP. arXiv:1902.00751.
- Hu, E. J., et al. (2021). LoRA: Low-Rank Adaptation of Large Language Models. arXiv:2106.09685.
- Li, X. L., & Liang, P. (2021). Prefix-Tuning: Optimizing Continuous Prompts for Generation. arXiv:2101.00190.
- Ruder, S. (2018). Transfer Learning Overview. https://ruder.io/transfer-learning/
- Wolf et al. (2020). Transformers: State of the Art NLP. arXiv:1910.03771
- Scikit-learn Documentation. https://scikit-learn.org
- Hugging Face Docs. https://huggingface.co/docs
- Zhang, X., et al. (2015). Character-level Convolutional Networks for Text Classification. arXiv:1509.01626.
Notas del Autor: Algunas técnicas de ampliación de datos y combinaciones híbridas (por ejemplo, adaptadores-LoRA) forman parte de mi investigación experimental y requieren validación adicional en entornos empresariales antes de considerarse como estándar.


コメント